

![]()
![]()
![]()
Vladislav Bambuch
web scraping, cryptocurrencies, crypto crime detection, microservices, apache kafka, data streaming
Bezpečnost Počítačové sítě Webové technologie Zpracování dat (obraz, zvuk, text apod.)
The goal of this work is to build a platform for collecting and displaying metadata about cryptocurrency addresses from public and also dark web. To achieve this goal, the author uses web parsing technologies written in PHP. Challenges accompanying a website parsing are solved by scaling capabilities of Apache Kafka streaming platform. The modularity of the platform is accomplished by microservice architecture and Docker containerization. The work creates a unique way how to search for potential crypto criminal activities, that appeared outside of the blockchain world, by building a web page application on top of this platform (that serves for managing the platform and exploring the extracted data). The platform architecture allows adding loosely coupled modules smoothly where the Apache Kafka mediates communication of the modules. The result of this article is meant to be used for cybercrime detection and prevention. Its users can be law enforcement authorities or other agencies interested in reputations of cryptocurrency addresses.

![]()
![]()
Juraj Holub
RetDec, reverse engineering, decompiler, x86, FPU, Avast
Bezpečnost Počítačová architektura a vestavěné systémy Překladače a gramatiky
V dnešnej dobe je proces analýzy nebezpečného softvéru dôležitou súčasťou informačných technológií. Jedna z kľúčových techník je spätný preklad škodlivých binárnych programov. Spätný preklad je komplexný proces, ktorým sa zaoberá niekoľko projektov. Projekt RetDec sa zameriava na flexibilný návrh a riešenie spätného prekladača s možnosťou znovupoužiteľnosti. Ide o open-source projekt vedený firmou Avast. Tento článok sa zaoberá návrhom nového rozšírenia pre spätný prekladač RetDec v oblasti podpory špecializovanej inštrukčnej sady pre jednotku FPU, ktorá je súčasťou procesorovej architektúry x86.

![]()
![]()
Tomáš Vlk
Continuous Integration, Continuous Deployment, Configuration Management, Infrastructure as Code, Nix, NixOS, NixOps
Informační systémy
Tato práce se zabývá uplatněním funkcionálního balíčkovacího systému Nix a jeho ekosystému (NixOS, NixOps) pro CI/CD při agilním vývoji. Při použití těchto technologií jsou problémy způsobené odlišným prostředím prakticky eliminovány bez nutnosti kontejnerizace. Práce obsahuje popis možností a nedostatků Nix/NixOps a navrhuje obecný postup použití těchto technologií pro jednotlivé fáze agilního vývoje a CI/CD. Díky Nix/NixOps je implementace CI/CD velmi jednoduchá a celý proces je navíc reprodukovatelný. Výstupem práce je sada příkladů demonstrující použití Nix/NixOps v různých projektech, a která je dostupná jako open-source. Díky této sadě mohou vývojáři použít Nix rychle a jednoduše v jakémkoliv projektu, bez nutnosti studia velkého množství materiálů.
![]()
![]()
Kateryna Polishchuk
SNMP, IoT zařízení, Monitorování sítě
Počítačové sítě
Tato práce řeší implementaci SNMP agenta pro monitorování IoT zařízení, komunikujících přes radiový signál Z-Wave. Podobná zařízení nepodporují protokol SNMP, proto podstatou agenta je shromažďovat informaci o zařízeních z IoT komunikace a ukládat je do proměnných v databázi MIB. Postup implementace agenta bude demonstrován na zařízeních dveřní senzor a signalizační zařízení ze sady inteligentní domácí bezpečnosti D-Link. Zařízení komunikují s USB-vysílačem Z-Wave, který je přípojen k počítací, a posílají o sobě události, jako například teplota, stav, typ senzoru atd. Pro vytvoření vlastního agenta SNMP byl použit nástroj Net-SNMP. Data o zařízeních jsem zpracovávala z nástroje Home Assistant, vyhodnocovala jsem události o zařízeních a ukládala informaci do databáze MIB. Vytvořené řešení poskytuje možnost kdykoliv zjistit aktuální stav zařízení pomocí standardních SNMP manažerů. Výsledná práce může pomoct organizacím používajícím IoT zařízení předejít nežádoucímu ohrožení IoT sítě. Výsledkem této práce je rozšíření Z-Wave komunikace o systém SNMP.
![]()
![]()
Sergey Panov
Abstract data-structures, Testing, IoT
Testování, analýza a verifikace
Testing multicomponent systems in IT and IoT that process the streams of different messages is a complicated task. Why it is complicated? Because of number of components, asynchronous interaction, different combinations of actions to test, test environment differs from real environment and others. This paper introduces an idea how to generate complex input data for system testing while requiring minimum intervention from a developer. The test data generation is based on analysis of traces of communication in a real system, and reproduction of similar traces for testing purposes. The paper also proposes a framework for initial analysis of messages transferred within the recorded communication. The problem can be solved using different abstract models: the message's model, the communication's model. The result of this work is the implemented library for creating a message's model with a set of operations for working with this model.

![]()
![]()
![]()
Roman Bártl
Arduino, Android, Bluetooth Low Energy, Vestavěný systém, Notifikace
Počítačová architektura a vestavěné systémy Uživatelská rozhraní
Cílem této práce je navrhnout a vytvořit notifikační zařízení, které bude zobrazovat nejrůznější upozornění z chytrých telefonů. Jedná se o upozornění na příchozí hovory, stav baterie a notifikace nainstalovaných aplikací. Jádrem zařízení je jednodeskový počítač Arduino. Součástí práce je i implementace aplikace pro operační systém Android, která slouží jak pro komunikaci s tímto zařízením, tak i k samotnému zachytávání zmíněných událostí. Pro komunikaci je použita technologie Bluetooth Low Energy. Je kladen důraz na jednoduchost a srozumitelnost celého systému včetně zajištění co největší možné kompatibility napříč verzemi systému Android.

![]()
![]()
Simeon Borko
enzyme mining, novel biocatalysts, web server
Bioinformatika
Millions of protein sequences are being discovered at an incredible pace, representing an inexhaustible source of biocatalysts. Despite genomic databases growing exponentially, classical biochemical characterization techniques are time-demanding, cost-ineffective and low-throughput. Therefore, computational methods are being developed to explore the unmapped sequence space efficiently. Selection of putative enzymes for biochemical characterization based on rational and robust analysis of all available sequences remains an unsolved problem. To address this challenge, I have developed EnzymeMiner – a web server for automated screening and annotation of enzymes that enables selection of hits for wet-lab experiments. EnzymeMiner prioritizes sequences that are more likely to preserve the catalytic activity and are expressible in a soluble form in heterologous host organism Escherichia coli. EnzymeMiner reduces the time devoted to data gathering, multi-step analysis, sequence prioritization and selection from days to hours. EnzymeMiner is a universal tool applicable to any enzyme family that provides an interactive and easy-to-use web interface freely available at https://loschmidt.chemi.muni.cz/enzymeminer/.
![]()
![]()
Michael Polák
Network Device Identification, k-Nearest Neighbors, Frequency Analysis
Bezpečnost Počítačové sítě
With the constantly growing number of devices on private and corporate networks, it is becoming increasingly more important for network administrators to track devices based on their behavior with limited feature availability due to the increasing security risks. This paper analyzes methods used to create device profiles that are subsequently used to identify devices using frequency analysis and the k-Nearest Neighbors algorithm with cosine similarity as the distance metric. Lastly, the results of this method are presented with possible improvements to the existing algorithm.

![]()
![]()
![]()
Dominik Vagala
Paint my room, Change wall color, Náhľad farby na stene, Rozšírená realita, AR, ArCore, Mobilná aplikácia, Android
Počítačová grafika Zpracování dat (obraz, zvuk, text apod.)
Cieľom tejto práce je návrh a implementácia mobilnej aplikácie pre Android, ktorá by umožňovala meniť farby na stene pomocou rozšírenej reality. Užívateľ si tak môže vyskúšať rôzne farby priamo v miestnosti kde sa nachádza, a následne sa rozhodnúť, ktorá farba sa mu tam najviac hodí na vymaľovanie stien. Na rozpoznanie hraníc steny je použitý Sobelov detektor hrán, kde sa ohraničený úsek steny vypĺňa farbou pomocou upraveného Queue-Linear Flood Fill algoritmu. 2D súradnice, kde užívateľ klikol na stenu, sa približne prepočítajú na 3D súradnice v priestore. Tie sa následne sledujú pomocou knižnice ArCore, vďaka čomu stena zostane zafarbená aj keď sa užívateľ pohybuje po miestnosti.

![]()
![]()
![]()
Ondřej Čech
Penitentes, Simulace tání, Ledovcové struktury
Modelování a simulace Počítačová grafika
Cílem práce je vytvořit simulaci toho, jak vznikají ledovcové struktury známé jako Kajícníci neboli Penitentes. Tyto útvary vznikají obvykle ve vysokohorském prostředí a podle posledních výzkumů jsou způsobeny odrážením slunečního záření uvnitř prohlubní na povrchu ledovce a jejich prohlubování sublimací při teplotách pod bodem mrazu. Byl implementován matematický model popisující toto chování, který vytvořila Meredith D. Betterton. Na tomto modelu byly poté provedeny experimenty, které měly za úkol potvrdit nebo vyvrátit, zda skutečně vede k vytvoření těchto útvarů. Jelikož původní model pracuje pouze s jednotlivými řezy, bylo třeba tento model upravit, aby se ovlivňovaly řezy navzájem. Vznik těchto útvarů stále není dokonale prozkoumán a práce, které se jím v průběhu let zabývaly, si v některých částech i protiřečí. Přitom vlastnosti těchto struktur zřejmě zpomalují tání ledovce, na kterém se nacházejí, což by v současné době mohly být cenné znalosti.
![]()
![]()
Filip Januš
Sociální síť, Soukromí, Bezpečnost, Skóre soukromí, Nastavení soukromí
Bezpečnost
V dnešní době stále přetrvává trend přesunu mezilidské komunikace do online prostředí. A to díky sociálním sítím a službám jimi poskytovanými. S tímto faktem souvisí i rostoucí počet uživatelů sociálních sítí. Mnoho uživatelů ovšem nevnímá rizika spojená s přítomností v internetovém prostředí. Tato práce se zaměřuje na analýzu bezpečnostních nastavení uživatelských účtů sociálních sítí a následné vyhodnocení tohoto nastavení. Cílem práce je vytvořit nástroj poskytující možnost vyhodnotit bezpečnostní nastavení uživatelského účtu na sociální síti případně doporučit vhodnější nastavení s ohledem na soukromí uživatele. Aby bylo možné dosáhnout těchto cílů, je potřebné použít vhodný model provádějící vyčíslení skóre privátnosti. Výstupem práce bude návrh a implementace nástroje provádějící analýzu, vyhodnocení a doporučení, jak vylepšit své nastavení soukromí na sociální síti. Což by mělo pomoci uživateli omezit množství uniklých citlivých informací.
![]()
![]()
Tomáš Dacík
Static Analysis, Deadlock Detection, Frama-C
Testování, analýza a verifikace
Frama-C is a platform for static analysis of source codes written in the C language. It provides a wide range of analysers usually based on EVA - Frama-C's value analysis plugin. Despite some attempts to support analysis of multi-threaded code have been done in Frama-C, the whole platform is currently limited to analysis of sequential code only. In this paper, we present Deadlock, a new plugin of Frama-C focused on deadlock detection. Together with the core algorithm of deadlock detection, we present a technique our analyser uses to handle multi-threaded code partially as a sequential one, which allows us to improve the precision of our analysis by using existing plugins of Frama-C. In our experimental evaluation, we show that our tool is able to handle real-word C code with a high precision.

![]()
![]()
Michal Janů
VR tour of FIT, VR FIT, FIT tour on Oculus Quest, VR Oculus quest, Unitybased VR application
Počítačová grafika
The main goal of this work is to make an application for VR headset Oculus Quest with the name FIT_VR. The application has several features that allow the user to do more than just walk freelyaround the FIT BUT areal, and these are Navigation and Instant travel. The Navigation feature isused to find the shortest route to an office or lecture room and instant travel allows to choose astarting location.
![]()
![]()
Pavol Karlík
Speech Enhancement, Deep Learning, Cycle-Consistency
Robotika a umělá inteligence Zpracování dat (obraz, zvuk, text apod.)
Speech enhancement aims to improve speech intelligibility and overall perceptual quality of speech by using various algorithms. Neural networks (NNs) have become a standard approach for solving such problems. NNs are usually trained by comparing the network output to the target sample. In our work, we incorporate cycle consistency constraint during the training period to improve the network robustness --- we add another NN to the process. The second NN performs an opposite task --- its goal is to introduce noise to clean speech recording. The networks are trained in a cycle, each taking the output of the other network as an input. Cycle-consistency, among other things, causes the network to see a much larger variety of noisy data, which improves the network's robustness. We perform experiments on both paired and unpaired data, which is enabled by adding adversarial training to the training. The DNN models are evaluated by using an automatic speech recognition system. The speech enhancement models trained and evaluated in this work are based on a recent publication. The results have shown that adding cycle-consistency improves the models' performance significantly.

![]()
![]()
Tomáš Sýkora
automatic speech recognition, domain adaptation, conversational speech
Zpracování dat (obraz, zvuk, text apod.)
Many state-of-the-art results in different machine learning areas are presented on day-to-day basis. By adjusting these systems to perform perfectly on a specific subset of the general data, huge improvements may be achieved in their resulting accuracy. Usage of domain adaptation in automatic speech recognition can bring us to production level models capable of transcribing difficult and noisy customer conversations way more accurately than the general models trained on all kinds of language and speech data. In this work I present 12.7% word error rate improvement in our speech recognition task over the general domain speech recognizer from Google. The improvement was achieved by both very precise annotation and preparation of domain data and by combining state-of-the-art architectures and algorithms. The described system was successfully integrated into a production environment of the Parrot transcription company founded by, among other team members, current and former faculty students, which drastically increased performance of the human transcribers.

![]()
![]()
![]()
Aneta Dufková
sentiment analysis, tweet sentiment, estimation of emotions
Zpracování dat (obraz, zvuk, text apod.)
This paper describes the process of estimation of emotions from a text using machine learning. Negative, positive, and neutral emotions are recognized from tweets focused on various topics. The whole work is not only about machine learning, but also about natural language processing. It involves data gathering, preprocessing of obtained texts, and a lot of experimenting with both model and dataset. The final model has been used to create a simple web application whatdoestwitterthink.com, which allows user to discover what do people on Twitter think. User can write a topic, the app downloads tweets related to this topic in real time, and analyzes them. The application also collects feedback from users to improve the classifier.

![]()
![]()
Dominik Gabzdyl
vehicle counting, counting by regression, convolutional neural networks
Robotika a umělá inteligence Zpracování dat (obraz, zvuk, text apod.)
Traffic analysis is still a challenging task. During such task there are many pitfalls to be aware of. Such as small image resolution, high number of overlapping objects, angle of camera, blurred objects due to their motion or weather conditions. This paper addresses the issue of counting vehicles instances in images and videos. Remarkable results and state-of-the-art methods are defined by convolutional neural networks. There are many approaches to address the issue of counting objects in images. One of which is counting by regression, which is the aim of this paper. I propose an architecture which is inspired by some state-of-the-art models. The proposed model improves accuracy on various datasets. For instance on the very small PUCPR+ dataset the Root Mean Square Error between expected and predicted vehicle counts was reduced from 34.46 to 8.84 vehicles (measured on the test set).

![]()
![]()
David Kozák
search engine, semantic enhancement, MG4J, compiler, indexation, searching, annotation, big data
Webové technologie
The topic of this paper is semantic searching over big textual data. It describes the design and implementation of a search engine Enticing that queries semantically enhanced documents efficiently and has a user friendly interface for working with the results. First, state of the art solutions along with their strengths and shortcomings are analyzed. Then a design for new search engine is presented along with a specialized query language EQL. The system consists of components for indexing and searching the documents, management server, compiler for the query language and two clients, web based and command line. The engine has been successfully designed, developed and deployed and is available via Internet. As a result of that, the possibility to use semantic searching is available to a wide audience.

![]()
![]()
Monika Mužikovská
ANaConDA, Dynamická analýza, Paralelní chyby, Víceprocesové programy
Testování, analýza a verifikace
Dynamická analýza se s úspěchem využívá pro detekci chyb ve vícevláknových programech. Algoritmy, které byly za tímto účelem navrženy, jsou ale často využitelné i pro víceprocesové programy. Žádný ze známých nástrojů pro dynamickou analýzu ale monitorování procesů nepodporuje. Cílem této práce bylo rozšířit nástroj ANaConDA o analýzu a monitorování víceprocesových programů. Výsledkem je implementace rozšíření, které za vývojáře analyzátorů řeší problémy spojené s oddělenými adresovými prostory a synchronizací pomocí semaforů. Rozšíření bylo využito pro úpravu analyzátoru AtomRace pro detekci časově závislých chyb nad daty ve víceprocesových programech a použito na experimenty se studentskými projekty z předmětu Operační systémy. Výsledky experimentů ukázaly, že se nástroj ANaConDA může stát vítaným pomocníkem při implementaci nejen víceprocesových projektů.
![]()
![]()
Michael Halinár
neurónová sieť, odtlačok prsta, rekonštrukcia
Robotika a umělá inteligence
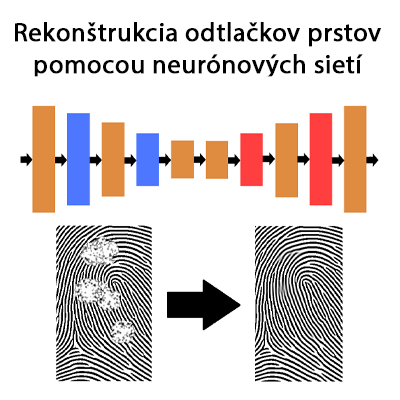
Táto práca sa zaoberá problematikou rekonštrukcie poškodených odtlačkov prstov s využitím neurónových sietí. Rekonštruované odtlačky sú syntetické, ako aj poškodenia, ktoré sú do odtlačkov vkladané. Sieť sa snaží z poškodeného odtlačku dostať pôvodný, pri zachovaní všetkých dôležitých aspektov odtlačku prsta. Táto práca rieši dva problémy a to výber vhodnej architektúry neurónovej siete a vytvorenie databáze syntetických odtlačkov. Keďže voľne dostupné databáze reálnych odtlačkoch sú nedostatočne veľké. Špecifická architektúra neurónovej siete je schopná rekonštruovať poškodené obrázky. Takáto architektúra sa nazýva autoencoder. Je to druh neurónovej siete, ktorá využíva konvolučné vrstvy. Po naučení dokáže veľmi dobre redukovať šum a rekonštruovať vstupy. V práci je použitý tento typ architektúry na rekonštrukciu poškodených častí odtlačku. Pre simuláciu poškodenia je vložená do odtlačku prstu bradavica. Sieť dokáže rekonštruovať poškodené časti pri zachovaní pôvodných vlastností prsta vo väčšine prípadov. Rekonštrukcia bradavice je závislá od miesta a veľkosti bradavice. Kvalita rekonštrukcie je meraná pomocou programu Verifinger. Táto práca ukazuje, že s použitím vhodnej neurónovej siete, ktorá bude naučená na dostatočne veľkej databáze, je možné dosiahnuť rekonštrukciu poškodeného odtlačku prsta. Odtlačky prstov sa počas života môžu meniť rôznymi spôsobmi. Vytvorená aplikácia dokáže eliminovať tento faktor, zrekonštruovať pôvodný odtlačok a umožniť lepšiu identifikáciu vlastníka odtlačku.

![]()
![]()
Kateřina Trávníčková, Oldřich Kodym
Segmentation, Deep learning, Medical data, Image restauration, Limited training set
Počítačová grafika Robotika a umělá inteligence Zpracování dat (obraz, zvuk, text apod.)
Deep learning based medical data segmentation methods can provide excellent results already. However, these results are obtained mostly thanks to the large training data sets. Obtaining the sufficient amount of correct annotations might be problematic in the medical field. This paper describes the problem of training medical segmentation models with limited annotations and proposes solutions to address the issue. We compare the baseline segmentation model group with two other model groups. These groups use different means to battle the lack of data problem. First group is pretrained in unsupervised manner and the second one uses human interaction in form of guidance clicks. We train 14 models for each group on subsets with varying number of patients. Segmentation model trained on small number of patients has better results when pretrained in unsupervised manner on the whole trainig set with 70 patients. Better results are obtained with the interactive method, where training on only two patients reaches Dice score 0.929 whereas the preitrained model reaches 0.830 and the baseline model only 0.749.

![]()
![]()
Michal Ormoš
RTLS Systems, UWB, CI/CD, Indoor Localization
Testování, analýza a verifikace
Fast development and deployment of the software are the new phenomena of the era. It is not different in the field of real-time localization systems (RTLS). In our global world where the global positioning system (GPS) is the everyday utility, there is a necessity of localizing under the roof where the GPS cannot access. Here come the local position systems based on Ultra Wide Band (UWB), which bring the ultimate precision. This work solves the problem of fast delivery of the software responsible for the RTLS System. It produces a case study on how to develop, test, and deploy this system in the fast CI/CD environment with the help of DevOps principles. This requires introducing the new techniques and methods for how to validate and test the precision of these systems.

![]()
![]()
Jan Rajnoha
Framework, Informační systém, Windows 10, UWP, Aplikační design
Informační systémy Uživatelská rozhraní
Informační systém je v dnešní době jeden z nejpoužívanějších typů aplikace a je potřeba zjednodušovat jejich návrhy a realizaci pomocí frameworků, kterých existuje celá řada, ale zatím neexistuje framework, který by byl schopný pracovat nad Windows 10 a technologií Universal Windows Platform. V tomto článku se zaměřím právě na návrh frameworku pro Windows 10 s požadavky na jednoduchost tvorby jednotlivých modulů, aktualizaci a automatickou tvorbu generovaných formulářů. Součástí řešení je i ukázková aplikace, která prezentuje možnosti frameworku jednoduchou formou včetně zdrojových kódů. Windows 10 je v aktuální době nejrozšířenější operační systém a nabízí velmi širokou škálu zařízení a je tedy výhodné směřovat právě na něj.

![]()
![]()
Michal Piňos
Neuroevoluce, Neuronové sítě, Evoluční výpočetní techniky
Robotika a umělá inteligence
Cı́lem této práce je návrh a implementace programu pro automatizovaný návrh konvolučnı́ch neuronových sı́tı́ (CNN) s využitı́m evolučnı́ch výpočetnı́ch technik. Z praktického hlediska tento přı́stup redukuje potřebu lidského faktoru při tvorbě CNN, a tak eliminuje zdlouhavý a namáhavý proces návrhu. Tato práce využı́vá speciálnı́ formu genetického programovánı́ nazývanou kartézské genetické programovánı́, které pro zakódovánı́ řešeného problému využı́vá grafovou reprezentaci. Tato technika umožňuje uživateli parametrizovat proces hledánı́ CNN, a tak se zaměřit na architektury zajı́mavé z pohledu použitých výpočetnı́ch jednotek, přesnosti či počtu parametrů. Navrhovaný přı́stup byl otestován na standardizované datové sadě CIFAR-10, která je často využı́vána výzkumnı́ky pro srovnánı́ výkonnosti jejich CNN. Prvotnı́ experimenty ukázaly, že vytvořená implementace (využı́vajı́cı́ GPU akceleraci) je schopna vytvořit či vylepšit přesnost CNN. Výsledkem experimentů, kdy bylo pro trénovánı́ k dispozici pouze několik epoch, byla řešenı́ s přesnostı́ 64.5 % a počtem parametrů 146K při využitı́ základnı́ch vrstev a řešenı́ s přesnostı́ 74.5 % s počtem parametrů 475K při využitı́ reziduálnı́ch vrstev. Záměrem těchto experimentů bylo dokázat funkčnost implementovaného programu a proof-of-concept navržené metody.
![]()
![]()
Lukas Erlich
Raspberry Pi, Laravel, Web manager, GUI, Raspbian
Počítačová architektura a vestavěné systémy Uživatelská rozhraní
Cieľom tejto práce je vytvoriť zábavný kufrík (hardware aj software), ktorý umožňuje spúšťanie retro arkádových hier a funguje taktiež ako jukebox na prehrávanie mp3 piesní. Jadro kufru je tvorené Raspberry Pi a k nemu pripojenými audiovizuálnymi a kontrolnými perifériami. Software pre konzolovú časť a jukebox je prevzatý z GitHub open-source projektov RetroPie a FruitBox. Nad operačným systémom je vytvorené jednoduché rozhranie a užívateľovi je taktiež umožnené spravovať kufor pomocou webového manažéra vo frameworku Laravel. Vytvoril som komplexný systém aplikácií, kominukujúcich s OS a hardwarovými komponentami. Hardwarová výbava kufra je kompletná a webový manažér je aktuálne z 80% hotový, rozhranie je udržiavané jednoducho. Práca ukazuje využitie jednoduchých počítačov v komplexnejších systémoch a ich možnosti.
![]()
![]()
Martin Gaňo
Neural networks, Optimization, Machine learning
Robotika a umělá inteligence Zpracování dat (obraz, zvuk, text apod.)
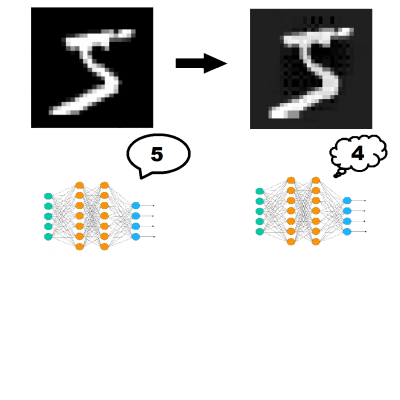
The main goal of this work is to design and implement the framework that yields robust neural network model against whatever adversarial attack, while result models accuracy is not significantly lower comparing to naturally trained model. Our approach is to minimize maximization the loss function of the target model. Related work and our experiments lead us to the usage of Projected gradient descent method as a reference attack, therefore, we train against data generated by PGD. As a result, using the framework we can reach accuracy more than 90% against sophisticated adversarial attacks on MNIST dataset. The greatest contribution of this work is an implementation of adversarial attacks and defences against them because there misses any public implementation.
![]()
![]()
![]()
Adam Ferencz
Počítání lidí, Počítačové vidění, Konvoluční neuronové sítě, Keras, Leaflet, OpenStreetMap
Robotika a umělá inteligence Uživatelská rozhraní
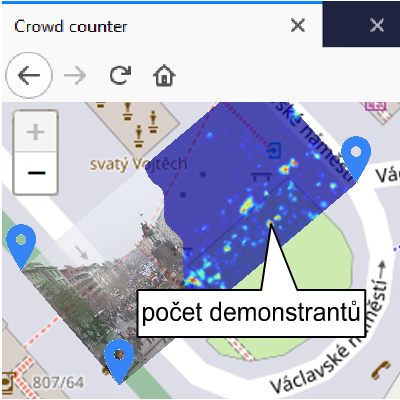
Cílem této práce je umožnit získat věrohodný odhad počtu lidí v davu na demonstraci či jiné hromadné akci z několika fotografií pořízených dronem, či jiných fotografií. Výsledkem jsou obarvené části mapy podle hustoty lidí v daném místě. Jednotlivé fotografie jsou dány do souvislosti s jejich umístěním do topologické mapy. Pro počítání lidí z fotky je použita metoda konvoluční neuronové sítě, která dokáže k fotografii vytvořit příslušnou mapu hustoty lidí. Integrace více fotek dohromady se pak provádí transformací do mapového podkladu, čímž se vezme v potaz i rozmístění davu v prostoru. Aplikace je rozdělena na server a webový klient. Serverová část se stará o analýzu davu a vytvoření map hustoty k jednotlivým obrázkům. Toho dosáhne pomocí natrénovaného modelu neuronové sítě Multi-Column Convolutional Neural Network. Klient se pak kromě vstupních obrázků stará o jejich zobrazení do mapy, případně modifikaci dat. Výsledkem je interaktivní mapa, ve které jsou umístěné mapy hustoty davu.

![]()
![]()
Ondřej Zemánek
visual counting, vehicle counting in static images, car park dataset
Počítačová grafika Zpracování dat (obraz, zvuk, text apod.)
This paper addresses the problem of counting vehicles in static images with no geometric information of the scene. Four convolutional neural network architectures were studied, implemented and trained as a main part of this work. Also, a dataset that consists of 19 310 images in total from 12 views that captures 7 different scenes were taken as part of this work. The trained networks map the appearance of the input sample to its corresponding vehicles density map, which can be easily translated to the vehicle count with keeping the localization of the vehicles in the input image. The main contribution of this work is in a comparison and application of the state-of-the-art solutions to the problem of object counting. Most of them were mainly designed to count pedestrians in crowded scenes or for medicine images, so the major goal was to adapt these solutions for vehicle counting task. The implemented models were trained on TRANCOS dataset which is a popular benchmark for counting vehicles on annotated low quality highway pictures. Their performance is compared and the results are discussed.

![]()
![]()
David Mikšaník
regular expressions, language inclusion, finite automata, counting automata
Testování, analýza a verifikace
We present an algorithm solving the inclusion problem for regular expressions with the counting operator limited to character classes, the so-called extended regular expressions (eREs), which are common in practice. Such regular expressions do not extend expressiveness beyond regularity, but allow one to succinctly express repeated patterns. Our algorithm is based on the transformation eREs into monadic counting automata (MCAs), i.e., finite automata with counting loops on character class where each counter is bounded. Similarly to the classical algorithm, we transform eREs into automata, but now we use MCAs instead of nondeterministic finite automata (NFAs). Following by building the product of MCAs and searching for a final state in the product. MCAs are compact representation of eREs because the number of states in MCAs does not depend on the bounds used in the counting operator, in contrast to NFAs where the number of states grows linearly. These bounds can be large in practice, thus MCAs are often significantly smaller than NFAs. We provide several examples for which the classical algorithm working with NFAs does not terminate in a reasonable amount of time, but our algorithm does. We also hope that our algorithm outperforms the classical algorithm in general, especially if the bounds of the counting operators are large.

![]()
![]()
Patrik Goldschmidt
TCP SYN Flood, DDoS Mitigation, Adaptive DoS Protection
Počítačové sítě
TCP SYN Flood is one of the most widespread DoS attack types performed on computer networks nowadays. The attack comes in many possible forms and several different mitigation methods to deflect it also exist. This paper discusses mentioned security incidents, various mitigation approaches, and presents a mechanism able to choose the most suitable method to mitigate the attack. The suggestion is made according to network traffic and the properties of mitigation methods. After the suggested method is deployed, the algorithm also monitors its behavior and may suggest a different strategy when the one currently in use proves to be ineffective. Our experiments have shown that the mechanism is able to successfully detect several attack variants and suggest a suitable method to deflect them while trying to minimize the impact on the end-user as much as possible. On the other hand, the suggestion accuracy is heavily dependent on available mitigation methods and their properties, which need to be set manually before the system can be used.

![]()
![]()
![]()
Lukáš Dobiš
Human classification, Computer vision, Deep learning
Zpracování dat (obraz, zvuk, text apod.)
This paper describes an approach for automated human recognition by using convolutional neural networks (CNN) to perform facial analysis of persons face in image data. The predicted biometric indicators are following: age, gender, facial landmarks and facial expression. CNN architectures with pretrained weights for each task are described. Age estimation CNN has new weights trained and freezed, then has added new LSTM layers into its architecture. New LSTM layers are trained and tested on newly created video data set. Solution for human recognition inference with single image and time series variants, in form of script with interconnected CNNs is explained and its inference speed performance supports further proposed expansion plans for live video inference.
Příspěvky na Excel@FIT procházejí recenzním řízením, ale nejsou považovány za finální publikaci výsledku. Příspěvek na Excel@FIT se nevylučuje s následnou publikací na vědecké či odborné konferenci nebo v časopise. Autorům kvalitních příspěvků na Excel@FIT a jejich vedoucím se naopak taková publikace doporučuje.
Submissions at Excel@FIT go through a reviewing proces, but they are not considered to be final publications of the result. Contributions presented at Excel@FIT do not exclude further publication at a scientific or professional conference or in a journals. Contrary to that, authors of high-quality contributions at Excel@FIT and their supervisors are encouraged to prepare such a contribution.