
![]()
Filip Kočica
sklad, optimalizace, simulace, generátor, objednávka, produkt, pickování, evoluce
Robotika a umělá inteligence
Tato práce řeší problematiku alokace produktů do lokací ve skladu za pomoci moderních meta-heuristických přístupů v kombinaci s realistickou simulací skladu. Práce poskytuje grafický nástroj umožňující sestavení modelu skladu, generování syntetických zákaznických objednávek, optimalizaci alokace produktů za pomoci kombinace state of the art technik, simulátor vytvořeného modelu skladu a nakonec nástroj pro hledání nejkratší cesty objednávky skrze sklad. Práce také uvádí porovnání různých přístupů a experimenty s vytvořenými nástroji. Podařilo se optimalizovat propustnost experimentálního skladu na téměř dvojnásobek (~57%). Přínosem této práce je možnost vytvoření modelu plánovaného či již existujícího skladu a jeho simulace i optimalizace, což může značně zvýšit propustnost skladu a pomoci detekovat a odstranit vytížená místa. To může vést k ušetření zdrojů či pomáhat v plánování. Dále tato práce přináší nový způsob optimalizace skladu a nové optimalizační kritérium.
![]()
Ondřej Sedláček
Service discovery, Network monitoring, SSDP, DNS-SD, NetBIOS
Počítačové sítě
Network monitoring plays a big part in network management, and considering the growing percentage of encrypted traffic, we find ourselves looking for new useful sources of data. This project practice focuses on the utility of service discovery protocols in this regard. It aims to find whether service discovery data can be extracted and used for network mapping, both alone and in combination with other measurements. We aim to collect as much relevant data as possible from a couple of selected service discovery protocols and to assign basic labels to devices. The collection is done using the NEMEA module Ipfixprobe and plugins we add to support our selected protocols. This data is then processed using an aggregating python module named SDP Analyzer. The result of our effort allows us to see what kinds of services devices query for and what kinds they advertise. We can also extract the device hostname, operating system and sometimes even get information about the specific device model. With some additional monitoring of the network, this information can be used to classify most devices in your network. This paper goes through the protocols used and details the interesting data that can be extracted. It also shows the aggregation and basic analysis of the data and it might bring use to anyone curious about what is happening on their local network.

![]()
Kateřina Kunorzová
FM-CW radar, detekce parkovacích míst, zpracování signálu
Zpracování dat (obraz, zvuk, text apod.)
Cílem práce je detekovat parkovací místa a využít k tomu radarové zařízení. Radar vysílá signál a ten se následně odráží od objektů v okolí radaru a je zpět přijímán. Po zpracování je k dispozici 2D/3D point cloud (prostor kolem radaru). Propojením této informace s rychlostí vozu či GPS polohou je možné získat posun automobilu a vypočítat souřadnice bodů z okolí. Následně lze tyto body postupně ukládat a zpřesňovat tak prostor, kudy auto projíždí. Výsledkem je mapa bodů, ve které lze pomocí vhodných metod detekovat volná parkovací místa. Propojením místa s příslušným GPS záznamem je k dispozici přesná GPS poloha volného místa. Výsledkem práce je systém analyzující radarová data. Přínosný může být jako vstup pro celkový systém monitorovaní volných míst, který by řidičům jeho využíváním ušetřil spoustu času.

![]()
David Bažout
video stabilisation, anomaly detection, crowded scenes, uav
Robotika a umělá inteligence Zpracování dat (obraz, zvuk, text apod.)
V posledních letech dochází k rychlému rozvoji využití dronů v mnoha odvětvích. Své uplatnění nachází i v oblasti národních bezpečnostních složek. Cílem této práce je návrh a implementace nástroje provádějícího analýzu davových scén. Tento nástroj zajišťuje včasnou identifikaci podezřelého chování osob a usnadňuje jeho lokalizaci. Zkoumaná scéna je rozdělena do mřížky složené z buněk, které uchovávají model obvyklého pohybu v dané oblasti. Na základě videodat je vypočten hustý optický tok, který je dále zakódován do příznakového vektoru. Porovnáním příznaku s modelem obvyklého pohybu je určena úroveň anomálie jednotlivých buněk. V rámci práce byl navržen a implementován kompletní systém umožňující detekci anomálie v davu a její vizualizaci do mapového podkladu. Mezi hlavní přínosy patří návrh vhodného algoritmu stabilizace videa, vývoj konvolučního autoenkodéru extrahujícího relevantní příznakové vektory a implementace modelu pozadí navrženého pro zpracování on-line dat.

![]()
Anton Firc
deepfake, cybersecurity, voice biometrics
Bezpečnost Robotika a umělá inteligence
Deepfake technology is on the rise, many techniques and tools for deepfake creation are being developed and publicly released. These techniques and tools are being used for both illicit and legitimate purposes. One of the unexplored areas of the illicit usage is using deepfakes to spoof voice authentication. There are mixed opinions on feasibility of deepfake powered attacks on voice biometrics systems providing the voice authentication, and minimal scientific evidence. The aim of this work is to research the current state of readiness of voice biometrics systems to face deepfakes. The executed experiments show that the voice biometrics systems are vulnerable to deepfake powered attacks. As almost all of the publicly available models or tools are tailored to synthesize the English language, one might think that using a different language might mitigate mentioned vulnerabilities, but as shown in this work, synthesizing speech in any language is not that complicated. Finally measures to mitigate the threat posed by deepfakes are proposed, like using text-dependent verification because it proved to be more resilient against deepfakes.
![]()
Vojtěch Staněk
3D Print, Education, Lesson, Teaching aid, 3D Print methodology
Počítačová grafika
3D printing has recently gained on popularity in various fields. However, to maximize the possibilities of the technology, specific skills are required. To prepare students for future employment, schools are trying to utilize 3D printing in teaching, but with little success, because there is no systematic approach. To solve this issue, a methodology for integration should be created, which covers technical, pedagogical and practical issues encountered by schools that tried to use 3D printing in their curriculum. For successful integration, it is necessary to provide complete lessons which can be immediately used in teaching. Those lessons are being made and five of them are already being tested. This article contains all required information to get started with 3D printing and its integration in primary and secondary schools. The methodology and the lessons make the technology more accessible, which could attract more schools to participate, possibly igniting discussion on the national level of integration.
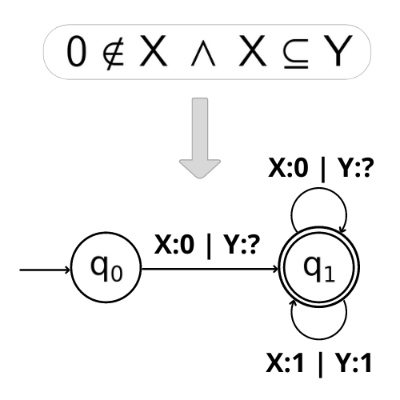
![]()
Barbora Šmahlíková
S1S, Büchi automata, decision procedure
Testování, analýza a verifikace
Automata on infinite words were introduced as a tool for proving the decidability of problems in various logics. They enable finite representation of a set of infinite words with a regular structure. The aim of this work is to show the process of translating a formula in monadic second-order logic of one successor (S1S) to a corresponding Büchi automaton and deciding its satisfiability/validity. We then compare our implementation with the implementation using loop deterministic finite automata for various formulae. The efficiency is measured mainly by the state count of the final automaton for each formula. Our implementation gives better results in the overall majority of the tested formulae in terms of the number of states of the final automaton.

![]()
Aleš Postulka
Rozšíření pro webové prohlížeče, Transparency and Consent Framework, Consent Management Platform, Souhlas se zpracováním osobních údajů
Webové technologie
Cílem této práce je návrh a implementace rozšíření pro webové prohlížeče Mozilla Firefox a Google Chrome. Účelem rozšíření je umožnění automatizované správy poskytnutých souhlasů se zpracováním osobních údajů. Souhlas se zpracováním osobních údajů je kvůli evropskému nařízení GDPR potřeba poskytovat na většině webových stránek. Za účelem usnadnění získávání souhlasu se zpracováním osobních údajů byl organizací IAB Europe vytvořen rámec Transparency and Consent Framework (TCF), který mimo jiné poskytuje rozhraní pro přístup k informacím o uloženém souhlasu. Vytvořené rozšíření interaguje s webovými stránkami využívajícími TCF. Umožňuje automatické poskytnutí souhlasu na základě nastavení, a také zobrazení informací o poskytnutém souhlasu. Rozšíření je publikováno v obchodu s doplňky pro prohlížeč Mozilla Firefox.
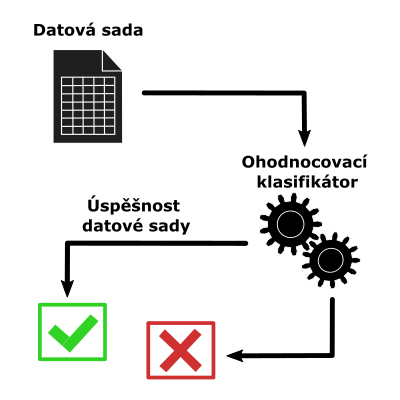
![]()
Jiří Setinský
DGA, strojové učení, genetické algoritmy, kvalita datových sad, predikce úspěšnosti
Zpracování dat (obraz, zvuk, text apod.)
V síti často probíhá komunikace mezi útočníkem a nakaženými počítači. Nelegitimní komunikaci mezi řídícím serverem a botnetem chceme odhalit a filtrovat. Jejich komunikace je založená na generování umělých doménových jmen pomocí DGA algortimů. Při detekci DGA adres je využito strojového učení. Pro přesnou klasifikaci je třeba vytvářet kvalitní trénovací datové sady. Jeden z přístupů, jak vytvořit datovou sadu je prostřednictvím genetických algoritmů. Při generování datových sad pomocí genetických algoritmů narážíme na problém s časovou náročností na určení kvality datové sady. Při velkém množství vygenerovaných datových sad přichází na řadu jejich otestování klasifikátorem. Cílem článku je najít vhodný způsob jak ohodnotit vygenerovanou datovou sadu bez toho, aniž by bylo potřeba použít klasifikátor pro otestování úspěšnosti. Budeme chtít najít parametry, jenž budou charakterizovat danou datovou sadu. Vyhodnocením parametrů pro více datových sad získáme trénovací datovou sadu, která bude sloužit pro natrénování klasifikátoru, který bude predikovat úspěšnost datové sady. Na vstupu klasifikátoru bude datová sada a na výstupu bude interval, který určí s jakou úspěšností bude datová sada ohodnocena.

![]()
Adam Sedláček
Kartézské genetické programování, Algebraická normální forma, Evoluční návrh, Kombinační obvod
Nekonvenční výpočetní techniky Robotika a umělá inteligence
Práce porovnává dva odlišné přístupy k zakódování kombinačních obvodů při automatizovaném návrhu obvodů, který využívá evolučních algoritmů. Porovnání proběhlo mezi kartézským genetickým programováním (CGP) a obvodem reprezentovaným v algebraické normální formě (ANF). Obě metody byly demonstrovány na čtyřech obvodech. Pro urychlení hodnocení kvality obvodů bylo využito paralelní simulace. Výhody a nevýhody obou metod zakódování jsou pak shrnuty v závěru této práce.

![]()
Adam Grünwald
chytrá domácnost, chytrý bojler, chytrá zásuvka, internet věcí
Počítačová architektura a vestavěné systémy Robotika a umělá inteligence
Cílem této práce je rozšířit chytrou domácnost o chytrý bojler, který vznikne připojením stávajícího hloupého bojleru do chytré zásuvky se speciálním modulem pro připojení teplotních čidel, která slouží k monitoringu vývoje teplot v bojleru. Takto vzniklý chytrý bojler se dokáže přizpůsobit zvyklostem v domácnosti tak, aby výsledkem byla úspora elektrické energie. V rámci práce byl navržen a implementován učící se algoritmus, který vyhodnocuje nasbíraná data a na jejich základě řídí ohřívání. Vliv na ohřev vody v bojleru mají také speciálně vytvořené události v kalendáři Google, se kterým se program synchronizuje a v okamžiku, kdy je celá domácnost například na dovolené, se voda v bojleru neohřívá. Program pro sběr dat, jejich vyhodnocování a řízení ohřevu, je spuštěn v počítači připojeném v místní síti. V něm se také nachází databáze pro získaná data a nástroj, zajišťující přehled statistik bojleru jako je aktuální stav či spotřeba elektrické energie za týden. Hlavním přínosem této práce je úspora elektrické energie snížením tepelných ztrát, díky menší průměrné teplotě vody v bojleru. Ta může ročně činit až 30 % nákladů, což pro 80 litrový bojler představuje roční úsporu až 3500 Kč. Původní bojler navíc získá chytré funkce, které současné chytré bojlery nenabízejí, nebo nabízejí jen v omezené formě.

![]()
Tomáš Vondráček
Identifikace uživatelů, Otisk prohlížeče, Otisk zařízení, Detekce webových rozšíření
Bezpečnost Webové technologie
Práce se zabývá vytvořením knihovny pro získávání informací o uživatelích na webových stránkách, kde získané informace mohou být použity pro identifikaci uživatelů. Navrhl jsem nové techniky získávání informací a optimalizoval některé aktuálně používané techniky. Implementovány jsou také techniky, kterými lze odhalit vedlejší efekty způsobené webovými rozšířeními, které maskují identitu uživatelů. Na základě analýzy webových rozšíření byly detekovány dříve neznámé informace, které mohou být taktéž použity pro identifikaci uživatele. Analyzovány jsou i získané informace o prohlížeči a zařízení z hlediska míry získané informace, doby jejich získání a stability v čase. Z výsledků analýzy lze optimalizovat množství získávaných informací, čímž lze omezit potenciální zpomalení webových stránek.
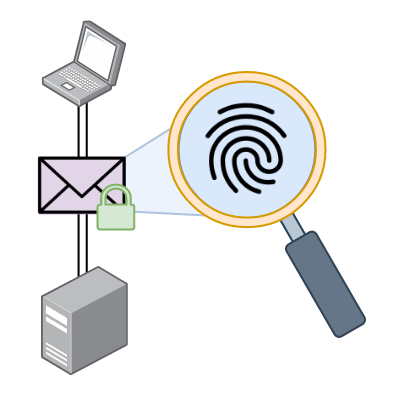
![]()
Lukáš Hejcman, Karel Hynek, Tomáš Čejka
TLS, Fingerprint, Identification, Cisco, Mercury, JA3, JA3cury
Bezpečnost Počítačové sítě
TLS is the most popular encryption protocol used on the internet today. It aims to provide high levels of security and privacy for inter-device communication. However, it presents a challenge from a network monitoring and administration standpoint, as it is not possible to analyse the communication encrypted with TLS at a large scale with existing methods based on deep packet inspection. Analysing encrypted communication can help administrators to detect malicious activity on their networks, and can help them identify potential security threats. In this paper, we present a method that allows us to leverage the advantages of two TLS fingerprinting methods, JA3 and Cisco Mercury, to determine the operating system and processes of clients on multiple networks. Our method is able to achieve comparable or better results than the existing Mercury approach for our datasets whilst providing more analysis opportunities than JA3. Furthermore, by using JA3 fingerprints, we open the door to the utilisation of this approach in the wider industry, where JA3 fingerprinting is predominant.

![]()
Vojtěch Čoupek, Vojtěch Čoupek
teaching of programming, pedagogical programming language, block programming, web application, syntax checking, 3D graphics, JavaScript, Karel language, elementary school, secondary school, beginners in programming
Překladače a gramatiky
The paper discusses the problem of teaching the basics of programming to the upper primary school and secondary school students. Firstly, it introduces Karel programming language, which is a tool that has been used since 1981, and some of its most important versions. Afterwards, the current trends employed in teaching the basic understanding of programming languages like block programming will be mentioned. Then, it presents a number environments used for this purposes and discusses their strong and weak points. The main goal is to create a new modern environment based on Karel programming language with up to date features that allow to teach programming in a playful and entertaining way.

![]()
Marek Schauer
JavaScript, ECMAScript, Web API, API usage, Web measurement, Browser, OpenWPM
Webové technologie
The world wide web is a complex environment. Web pages can access many APIs ranging from text formatting to access to nearby Bluetooth devices. While many APIs are used for legitimate purposes, some are misused to track and identify their users without their knowledge. In this paper, we propose a methodology to measure the usage of JavaScript APIs on the public web. The methodology consists of an automated visit of several thousand websites and intercepting JavaScript calls performed by the pages. We also provide a design and architecture of a measurement platform that can be used for an automated visit of a list of websites. The proposed platform is based on OpenWPM. The browser is instrumented by OpenWPM and a customized Web API Manager extension is responsible for capturing JavaScript API calls.
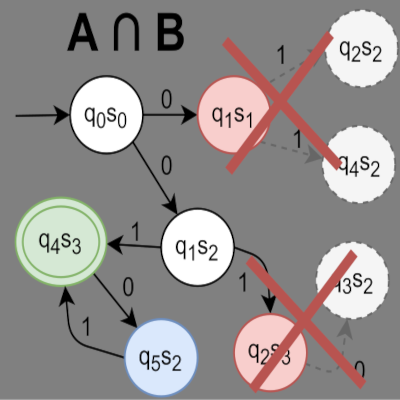
![]()
David Chocholatý, Lukáš Holík
Finite Automata, Product Construction, Emptiness Test, Intersection Computation Optimization, State Space Reduction, Length Abstraction
Nekonvenční výpočetní techniky Překladače a gramatiky
Finite automata are a well-known field of computational theory, and we use them widely in many situations. We will focus our attention to different heuristics for optimizing several typical problems with finite automata. We are interested especially in computation of intersection of automata product construction and its emptiness test, which is time and again required in modern computation technologies, but requires a lot of computational time and generates vast yet unnecessary so-called state space in the end. For this reason, we will try to use length abstraction for solving these problems and optimizing the product construction and its emptiness test as good as possible using solely knowledge about recognized words lengths.
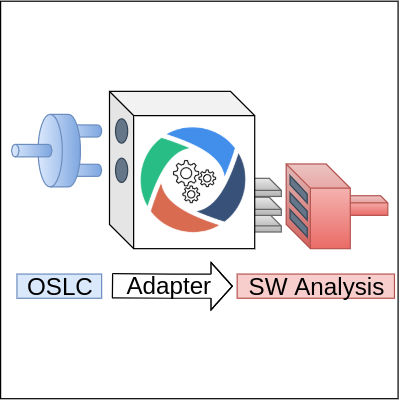
![]()
Ondřej Vašíček
OSLC, OSLC Adapter, OSLC Provider, OSLC Server, OSLC Consumer, OSLC Client, OSLC Automation, Eclipse Lyo, tool integration, software analysis and verification, ANaConDA, Facebook Infer, Perun, Valgrind
Testování, analýza a verifikace
The goal of this work is to provide an easy way of adding an OSLC compliant interface to an analysis tool. Such interface allows tools to be easily integrated with other tools or systems; allows them to be used remotely due to its web based nature; and allows them to be easily connected with a~database for persistency and queries. In this paper, we present an OSLC adapter which can be used to easily add an OSLC interface to most analysis tools. The adapter was designed and created using Eclipse Lyo and is universal enough to accommodate functionality of most analysis tools using the OSLC Automation domain interface by leveraging their current command-line interfaces. In this paper, we see the universality from the point of view of interoperability and development stage (compile-time and run-time). This work provides a~very brief introduction to OSLC and Eclipse Lyo; defines requirements and differences of analysis tools; covers the design of the adapter; and presents a~working implementation of the adapter. The most important evaluation indicator is that the current working version of the adapter is already being used in practice in four use cases, i.e. integration of tools ANaConDA, Perun, Spectra (all three developed by VeriFIT); and HiLiTE (Honeywell).
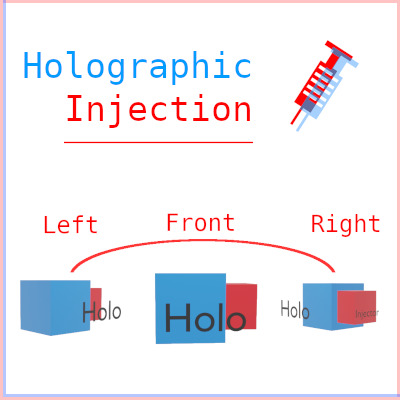
![]()
Roman Dobiáš
OpenGL, autostereoscopic display, single to multiview conversion, automated conversion, pipeline injection, API call hooking
Počítačová grafika
The adaptation of upcoming autostereoscopic displays by regular users depends on the availability of supported applications. To increase such a set, this paper describes compatibility software which turns (semi) automatically the output of regular OpenGL 3D applications to display-native output, which takes advantage of true 3D displays capabilities. This is achieved using a conversion layer that intercepts parts of OpenGL API and translates such API calls to ones that produce a multiview output of the original application.
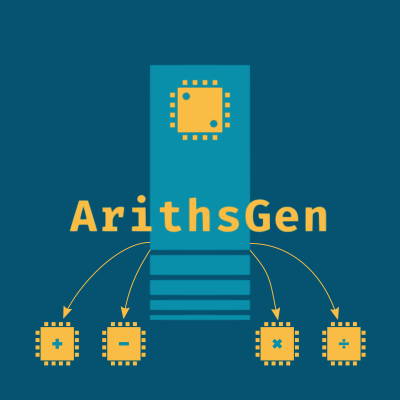
![]()
Jan Klhůfek
Generátor, Aritmetické obvody, Python, Zploštělý popis, Hierarchický popis, Jazyk C, Verilog, BLIF, Kartézské Genetické Programování (CGP)
Počítačová architektura a vestavěné systémy
Aritmetické obvody jsou nedílnou součástí dnešních procesorů. Konkrétně je zde najdeme uvnitř aritmeticko-logické jednotky (ALU), jednotky pro generování adres (AGU) či v matematickém koprocesoru (FPU). Mimo procesor se ale taktéž nachází v systolických polích, grafických akcelerátorech a akcelerátorech neuronových sítí pro paralelní rychlé výpočty. Hardwarové řešení aritmetických obvodů umožňuje vykonávat kýžené aritmetické operace mnohonásobně rychleji než softwarové řešení. Tato práce představuje open source nástroj, implementovaný v jazyce Python, schopný generovat aritmetické obvody a exportovat je do různých reprezentací popisu. Výstupní reprezentace pak slouží ke snadnému ověření funkčnosti navrženého obvodu (C), k popisu hardwaru a logické syntéze (Verilog), k formální verifikaci (BLIF) či ke globální optimalizaci obvodu s využitím evoluční strategie (CGP).
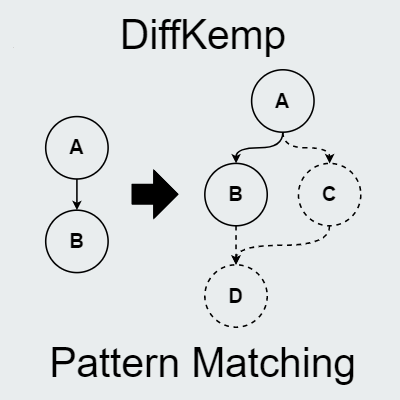
![]()
Petr Šilling
DiffKemp, LLVM, GNU/Linux kernel, Pattern Matching, Semantic Equivalence
Testování, analýza a verifikace
For some software projects, it might be crucial to ensure semantic stability of their core components between multiple release versions. Nowadays, semantic stability may be checked automatically even on large real-world projects using scalable tools, e.g., DIFFKEMP, which focuses on checking semantic equivalence of different versions of the Linux kernel. However, while these tools are highly scalable, they do tend to report some false-positives. Therefore, in this paper, we propose a static analysis method for matching patterns of recurrent changes between different versions of code. The proposed solution introduces a novel pattern matching algorithm based on gradual comparison of instructions according to their control flow and a method for encoding code change patterns into the LLVM intermediate representation. The proposed analysis has been implemented as an extension of DIFFKEMP, where we demonstrate how it may eliminate a substantial amount of non-equivalence results, which would generally require manual inspection.

![]()
Silvie Němcová
Neural Network Training, Loss Function, Training Process Examination
Robotika a umělá inteligence
The neural network training process involves a highly dimensional non-convex optimization problem. The training is a highly computationally demanding task with a risk that the optimization algorithm will be stuck at a local optimum or a saddle-point. Despite these concerns, modern neural networks are trained successfully only using straightforward training with SGD algorithm and regularization. A simple technique for analyzing the training process is presented in this paper, it consists of a linear interpolation of the parameters of a neural network. The developed tool examines the training process on the level of layers and individual parameters. The results obtained in the experiments confirm that the linear path of training is avoiding local optima, identifies the ambient and robust layers in the neural network and the results are consistent with the examination on the level of layers.

![]()
Pavel Eis
Automatizovaná anotace síťových zařízení, Klasifikace zařízení, Statistická klasifikace
Počítačové sítě
Automatická klasifikace zařízení v počítačové síti lze využít pro detekci anomálií v síti a také umožňuje aplikaci bezpečnostních politik dle typu zařízení. Pro vytvoření klasifikátoru zařízení je stěžejní kvalitní datová sada, jejichž veřejná dostupnost je nízká a tvorba nové datové sady je složitá. Cílem práce je vytvořit nástroj, který umožní automatizovanou anotaci datové sady síťových zařízení a vytvoření klasifikátoru síťových zařízení, který využívá pouze základní údaje o síťových tocích. Výsledkem této práce je modulární nástroj poskytující automatizovanou anotaci síťových zařízení využívající systém ADiCT sdružení Cesnet, vyhledávače Shodan a Censys, informace ze služeb PassiveDNS, TOR, WhoIs, geolokační databáze a informace z blacklistů. Na základě anotované datové sady je vytvořeno několik klasifikátorů klasifikujících síťová zařízení podle používaných služeb. Výsledky práce nejen výrazně zjednodušují proces vytváření nových datových sad síťových zařízení, ale zároveň ukazují neinvazivní přístup ke klasifikaci síťových zařízení.
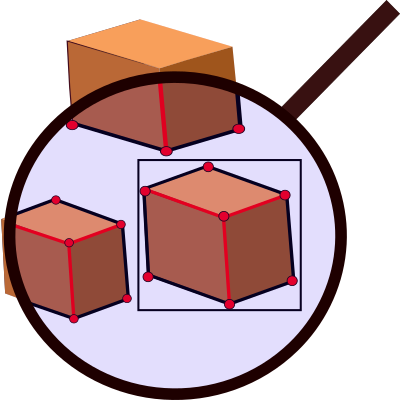
![]()
Adam Žitňansḱý
Shape Model Detection, Cuboid Detection, Stacked Hourglass Network
Zpracování dat (obraz, zvuk, text apod.)
This work addresses the problem of cuboid detection, more specifically detection of boxes in RGB images. The main result is the implementation of a system for detecting boxes and their accurate localization based on the detection of cuboid primitives: corners and edge points. The system consists of a detector of corner and edge points based on convolutional neural networks. Such detected primitives are processed into a model of the cuboid. Our system was trained and evaluated on a custom dataset of packaging boxes which was created as a part of this work. The trained model achieved PCK 90 % and recall 86 % for corners resp. 97.5 % and 96 % for edge points on unseen data.

![]()
Jiří Kutálek
Yoga Poses Detection, Video Annotation Application, Training CNN for Yoga Poses Recognition
Zpracování dat (obraz, zvuk, text apod.)
In this paper, the concept of a smartphone app detecting Yoga poses and displaying several frames to a user is presented. The goal of this project is proving that even a simple Convolutional Neural Network (CNN) model can be trained to recognize and classify video frames from a Yoga session. I created an application in which the videos are manually annotated. The data, consisting of frames captured from 162 collected videos based on the annotations, is then passed to train a CNN model. The Dataset consists of 22 000 images of 22 different Yoga poses. The frames are captured using the OpenCV library, the training process is handled by the TensorFlow platform and the Keras API, and the results are visualized in the TensorBoard toolkit. The Model’s multi-class classification accuracy reaches 91% when the binary cross-entropy loss function and the sigmoid activation function are used. Despite the experimental results are promising, the main contributions are the dataset forming tools and the Dataset itself, which both helped to confirm the proof-of-concept.
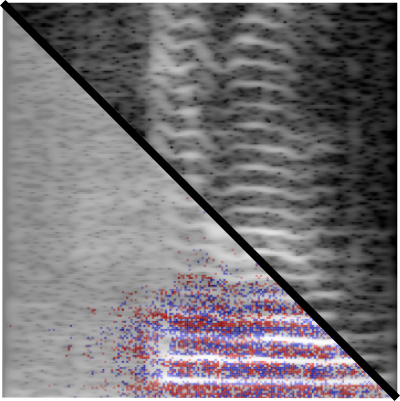
![]()
Marek Sarvaš
neural network interpretation, Layer-wise Relevance Propagation, deep neural networks, speech classification
Zpracování dat (obraz, zvuk, text apod.)
The growing problem of the popularity of using deep neural networks is their black box representation. The lack of transparency is raising questions about their reliability, credibility, or vulnerability to adversarial attacks. This caused rising demand for neural network explainability. The goal of this paper is to replicate existing experiments on a gender classification model and extend these experiments to analyze and uncover vulnerabilities of a network trained for gender classification on audio signal spectrograms. The easiest way to explain something is through visualization. For this, a layer-wise relevance propagation technique was chosen in this work because it produces easy-to-understand heatmaps of features relevant to a neural network. The heatmaps are produced by back-propagating relevances through a network from the output to the input layer. Two neural network models with AlexNet and ResNet architecture were used. Experiments with AlexNet model show that the network's predictions are highly dependent on a small number of time-frequency (TF) bins. By augmenting the training data using obtained relevance maps, I managed to lower the dependency on these bins. As a result, the prediction accuracy, when these bins were not present, was increased by $15\%$. The proposed approach can potentially lead to increased robustness of models, preventing or reducing the impact of adversarial attacks. Interpretation of ResNet model showed dependencies on lower frequencies and time. Producing interpretable heatmaps of the ResNet model required the implementation of more robust LRP rules.
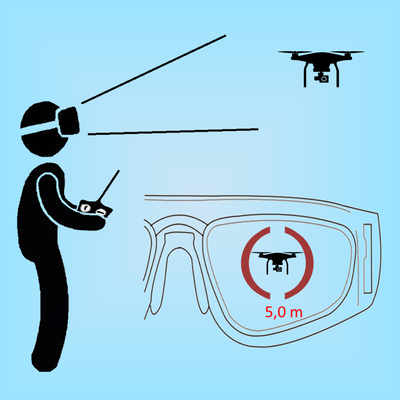
![]()
Marek Václavík
Microsoft Hololens 2, ovládání dronů, navigační prvky
Počítačová grafika Uživatelská rozhraní
Ovládání drona může být nelehký úkol a spolu s rozrůstající se škálou využití a zájmem o tyto bezpilotní letouny, se zvedá zájem i o dokonalejší a vyspělejší nástroje určené k jejich ovládání. V mnoha odvětvích se na repetetivní úkoly drona využívají auto-pilotní programy, které zajistí určitou míru automatizace. Zůstává stále mnoho situací, kdy je zapotřebí ovládat drona manuálně, tedy s přítomností osoby, která letoun ovládá. Takový pilot je právě nejvíce závislý na nástroji, který k ovládaní drona využívá a ve většině případů nepotřebuje pouze drona ovládat, ale mít dostatek údajů jak o letounu, tak o jeho okolí. Cílem této práce je prozkoumat možnost využití rozšířené reality, jakožto prostředí pro nástroj ulehčující pilotovy s dronem operovat a plnit různá zadání. Pro zobrazení rozšířené reality budou požity brýle Microsoft HoloLens 2. Pomocí těchto brýlí jsou uživateli zobrazovány v reálném čase letové údaje o letounu, možné detekované překážky, orientační prvky, prvky mise, apod. Tato aplikace je schopná otestovat, v jaké míře je využití rozšířené reality pro pilotování drona efektivnější oproti běžně používaným nástrojům, které zobrazují údaje z letounu v 2D formě na displej telefonu, tabletu, apod..
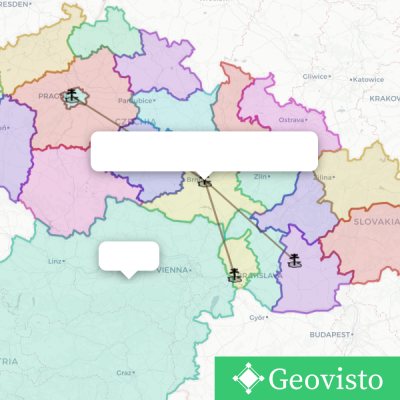
![]()
Andrej Tlčina
Authoring system, Geospatial objects, Web application
Uživatelská rozhraní Webové technologie
The goal of this project is to create an authoring system that will help users to create thematic maps with custom geospatial objects and custom datasets. This paper presents an authoring system that provides tools for creating simple and complex geospatial objects. The system allows users to import their datasets, containing custom data, like data about sales, wages, population, to mention few. Upon creating the needed geospatial object, the user then can use the mentioned imported data and map certain information onto the object. The project can help people like architects, cartographers, and academic users, who need thematic maps, so they can better communicate their ideas. For example, students can create thematic maps containing states that do not exist anymore. The project is an extension of the project Geovisto which uses predefined data for data visualization. This predefined data can be modified only by rewriting code. The extension will bring the possibility of creating custom graphical features or editing predefined ones, which can be used in other parts of the project. At the current stage of implementation, the system provides several tools for creating geospatial objects. It can import a dataset and apply an identifier which then maps the corresponding data onto the object. In addition, the user can export the state of the map and object and later import it.
![]()
Richard Hauerland
Vizualizace, Analýza trajektorií, Filtrace, Formalismus
Překladače a gramatiky Robotika a umělá inteligence Uživatelská rozhraní Zpracování dat (obraz, zvuk, text apod.)
Cílem této práce je navrhnout gramatiku a uživatelské rozhraní pro filtrování a vizualizaci časoprostorových dat. Konkrétně se budeme zabývat vyhodnocováním dopravních dat na základě analýzy trajektorií. Důležitou částí práce je návrh a popis formalismu, který umožňuje prostorovou filtraci a filtraci na základě statických a dynamických atributů. Na základě vytvořeného formalismu provedeme návrh aplikace s uživatelským rozhraním určené k analýze dat. Návrhu uživatelského rozhraní bude předcházet srovnání nejvýznamnějších existujících řešení.
![]()
Jan Zavřel
EIGRP, Simulation, Routing, OMNeT++
Modelování a simulace Počítačové sítě
This paper deals with the implementation and the evaluation of a simulation model of a modern dynamic routing protocol designed by Cisco Systems, Inc. called Enhanced Interior Gateway Routing Protocol (EIGRP) in a discrete simulator OMNeT++ implemented in C++. The resulting simulation model can be used to conduct various experiments which allow network designers and alike to explore the protocol's behavior in different situations inside a safe discrete environment. In order to produce a trustworthy simulation course, the protocol model must be as accurate as possible to the real implementation and thoroughly tested. This paper provides a basic overview of both protocol EIGRP and simulator OMNeT++. It also discusses the state of the model before and after the integration into a newer version of the INET framework, showcases improvements, and outlines the testing methodology.
![]()
Martin Dvořák
curtaining efekt, syntetické snímky curtaining efektu, konvoluční neuronová síť
Robotika a umělá inteligence
Tomografická 3D analýza v nanometrovém měřítku využívá snímky vzorků získané s využitím fokusovaného iontového svazku (FIB), při jejichž snímání ale dochází z fyzikálních důvodů k poškození "curtaining" efektem. Tento článek představuje nový přistup k odstranění curtaining efektu ze snímků pomocí strojového učení. Pro jeho odstranění je využita konvoluční neuronová síť (CNN) a technika učení s učitelem. Navržená síť pracuje s příznaky, které vytváří vlnková (Wavelet) transformace a jejím výstupem je vizuálně "vyčištěný" snímek. K učení sítě je využita syntetická datová sada poškozených snímků, které jsou vytvořeny generátorem simulujícím fyzikální proces tvorby reálného snímku. Simulace se skládá z "opotřebení" vzorku pomocí fokusovaného iontového svazku (FIB) a zobrazení povrchu pomocí skenovacího elektronového mikroskopu (SEM). Nově vytvořený přístup velmi dobře pracuje i s reálně pořízenými snímky. Kvalitativní vyhodnocení představeného řešení a srovnání s jiným řešením hodnotili laici i experti na tuto problematiku. Představené řešení představuje nový nadějný přístup k odstranění curtaining efektu a přispívá k lepšímu postupu zpracování i porozumění snímkům pořízeným při materiálové analýze.

![]()
Ľuboš Mjachky
Privacy Preservation, Machine Learning, Generative Adversarial Networks
Bezpečnost
Biometric-based authentication systems are getting broadly adopted in many areas. However, these systems do not allow participating users to influence the way their data are used. Furthermore, the data may leak and can be misused without the users’ knowledge. In this paper, we propose a new authentication method that preserves the privacy of individuals and is based on a generative adversarial network (GAN). Concretely, we suggest using the GAN for translating images of faces to a visually private domain (e.g., flowers or shoes). Classifiers, which are used for authentication purposes, are then trained on the images from the visually private domain. Based on our experiments, the method is robust against attacks and still provides meaningful utility.
![]()
Michal Šedý
nondeterministic finite automata, minimization, state merging, SAT solver
Testování, analýza a verifikace
Nondeterministic finite automata (NFA) are widely used in computer science fields, such as regular languages in formal language theory, formal verification, high-speed network monitoring, image recognition, hardware modeling, or even in bioinformatic for the detection of the sequence of nucleotide acids in DNA. Automata minimization is a fundamental technique that helps to decrease resource claims (memory, time, or a number of hardware components) of implemented automata. Commonly used minimization techniques, such as state merging, transition pruning, and saturation, can leave potentially minimizable automaton subgraphs with duplicit language information. These fragments consist of a group of states, where the whole language of one state is piecewise covered by the other states in this group. The paper describes a new minimization approach, which uses SAT solver Z3, which provides information for efficient minimization of these so far nonminimizable automaton parts. Moreover, the newly investigated method, which only uses solver information and state merging, can minimize automata similarly and with a transition density up to 2.5 (from each state lead approximately 2.5 transition edges) faster than a tool RABIT, which uses state merging and transition pruning.

![]()
Ivan Manoilov
Data processing, Analytical dashboards, Network Forensic Data
Počítačové sítě Uživatelská rozhraní Zpracování dat (obraz, zvuk, text apod.)
The goal of this project is to develop a system for processing various forensic data inputs (such as PCAP) and presenting them in a user-friendly, graphical way. Modern systems for visualization of data are too generic for this specific use-case and can't be employed for analysis of forensic data. This problem is solved via development of the system of analytical dashboards which represent the data, processed by various back-end services, responsible for parsing input, aggregating data and transforming it to the format acceptable by dashboards. Result of this thesis would be a highly extensible system, providing deep analytical view of network traffic, which enables the end-user to see underlying anomalies or problems of the traffic.
![]()
Adam Ferencz, David Bažout
Analýza davu, Počítačové vidění, Konvoluční neuronové sítě, Vizualizace v mapě, Uživatelské rozhraní, Leaflet, Webová aplikace
Uživatelská rozhraní Webové technologie Zpracování dat (obraz, zvuk, text apod.)
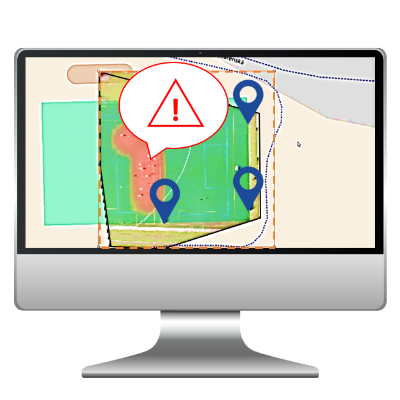
Cílem této práce bylo vytvořit aplikaci, která bude sloužit k detekci anomálie v davu z video streamu dronu pozorujícího scénu ze střední výšky. Aplikace nejenže analyzuje videozáznam, ale také ho promítá do místa v mapě. Slouží tedy nejdříve jako konfigurační nástroj a následně jako vizualizační nástroj. Celá aplikace je složená ze tří hlavních částí, kterými jsou výpočetní modul, webový server a webový klient. Tento celek pak dále komunikuje se serverem Vian, který je centrální i pro další projekty, které se věnují analýze videa.
![]()
Ján Pavlus
speech separation, mixture of mixtures, neural networks
Zpracování dat (obraz, zvuk, text apod.)
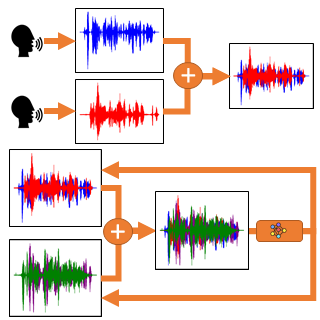
Speech classifier systems often fail on overlapped speech signals of more speakers as an input. For that reason, there are speech separation systems separating each speaker’s signal from others to provide better input signals for further speech classification. In these separation systems, neural networks turn out to perform quite well. To train these networks it is necessary to have parallel mixtures and single speaker’s signals as inputs and targets. Unfortunately, this criterion can not be frequently met for real mixtures. That also happens to be the reason why the training of the neural network is usually performed on artificial mixtures. In this article, the mixture of mixtures method has been used to provide the required training on the unsupervised mixtures. This method was presented in the article Unsupervised Sound Separation Using Mixture Invariant Training. This particular method mixes two existing mixtures into one called the mixture of mixtures and it is further being used as an input for the neural network. The original mixtures are used as training targets. Such a method enables training speech separation neural networks on full or partly unsupervised datasets. The unsupervised mixtures can be real recordings, which could lead to better separation results for real data during test time. We combine the mixture of mixtures method with ConvTasnet and perform experiments on the fully unsupervised and semi-supervised datasets generated from the WSJ0-2mix dataset. In our experiments, this method fails on the fully unsupervised dataset and it also does not have any positive impact on the experiments with the semi-supervised datasets. We discuss the possible reasons for the failure and outline the future work.

![]()
Daniel Dolejška
darknet, dark web, dark marketplace, cryptomarket, forensic analysis, crawling, scraping, purchase detection, cryptocurrency, blockchain, transaction, correlation
Počítačové sítě
Overlay networks (like Tor or I2P) create a suitable environment for criminality to thrive on the Internet. Dark marketplaces (a.k.a. cryptomarkets) are one such example of criminal activities. They act as an intermediary in the trade of illegal goods and services. This project focuses on forensic analysis of such web services and subsequent extraction of non-trivial information about the realised orders and payments from selected marketplaces. The main goal is to pinpoint the time interval when an order has been completed on selected marketplaces and its following correlation with cryptocurrency blockchains. The implemented program provides fully automated non-stop monitoring of selected cryptomarkets. That, under certain conditions, allows detection of realised purchases, detailed product and vendor monitoring and collection of various meta-data entries. Law enforcement agencies can use acquired data as support evidence regarding the operation of selected cryptomarkets and their vendors. The acquired information can also indicate current trends in products supply and demand.
![]()
Oliver Rainoch
AR, Navigace uvnitř budov, Mobilní aplikace, Android, Rozšířená realita, Unity, ARCore
Uživatelská rozhraní
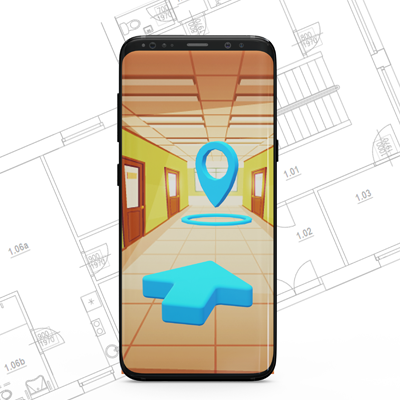
Tato práce se zabývá využitím rozšířené reality pro navigaci v budovách. Cílem je vytvořit mobilní aplikaci s prvky rozšířené reality pro navádění uživatele. K určení polohy jsou využity vizuální markery a technologie SLAM. Výsledná aplikace je implementována s pomocí knihovny ARCore a herního enginu Unity. Uživatel naskenuje marker, vybere hledanou místnost a pomocí plánku a šipky v rozšířené realitě je naváděn k cíli. Díky aplikaci je možné se efektivně a snadno dostat k hledané místnosti. Použité principy mohou být využity k navigování i v rozsáhlých areálech škol, společností a skladech.

![]()
Martin Macháček
zoo, informační systém, webová aplikace, mobilní aplikace, interaktivní mapa
Informační systémy Uživatelská rozhraní Webové technologie
Zoologické zahrady nabývají důležitého ochrannářského poslání, potřebují se ale taktéž prezentovat a poskytovat návštěvníkům zajímavé informace v podobě kapesního průvodce. Způsob správy těchto informací, spolu s její prezentací těmto návštěvníkům, je ovšem velmi často nedostačující. I přesto, že velké množství zahrad spadá pod unii CSZOO, tak nejsou schopné vytvořit sjednocený způsob prezentace informací jejich návštěvníkům. Tato práce se tímto problémem zabývá a poskytuje řešení -- sjednocující informační systém pro jakoukoliv zoo spolu s jednotnou mobilní aplikací s novodobým designem, která slouží jako kapesní průvodce a efektivní zdroj zajímavých informací v zoo. Důležitou součástí systému je možnost lokalikace na mapě, ať už zvířecích druhů, expozicí, nebo například stánků se suvenýry. Vytořený informační systém je spolu s veřejnou API založen na frameworku Lumen, mobilní aplikace je multiplatformní díky technologii Cordova. Mapové komponenty jsou vytvořeny s pomocí knihovny Leaflet spolu s OpenRouteService a mapových dat a dlaždic projektu OpenStreetMap. Návrh systému spolu s aplikací byl konzultován primárně se Zoo Brno. Byly sestaveny i dotazníky pro zoo a návštěvníky, které dokázaly upřesnit požadavky na jednotlivé části implementovaných řešení. V prvotní fázi bylo telefonicky konktaktováno celkem 20 zoo, z toho 7 uvedlo, že je tento systém zajímá a rádi by se dozvěděli více.
![]()
Pavol Dubovec
Počítanie objektov, Počítanie vozidiel, Tvorba aplikácií, Deep Learning
Počítačová grafika Uživatelská rozhraní Zpracování dat (obraz, zvuk, text apod.)
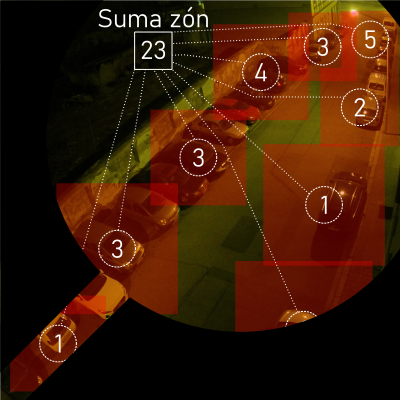
Cieľom tejto práce je vytvoriť aplikáciu, ktorá z obrazu zistí počet vozidiel na zvolenej fotografii. Takéto zisťovanie bude prebiehať klasifikáciou, pomocou konvolučnej neurónovej siete. Trénovacie dátach pozostávajú z fotografii parkovísk z rôznych pohľadov a pozícií. Riešenie bolo navrhnuté tak, že sa obrázky s parkoviskom rozdelia na niekoľko záujmových oblastí a z týchto oblastí sa vytvoria výrezy, pomocou vytvorenej aplikácie špecializovanej na túto úlohu. Následne prebehne anotácia obrázkov vytvorených týmto spôsobom, pomocou vytvorenej hodnotiacej aplikácie. Obrázky sa následne naformátujú na rovnakú veľkosť. Tieto pripravené výrezy sú následne predané knižnici na pre prácu s ML, Tensorflow, pomocou ktorej prebieha trénovanie modelu. Cieľom bolo vytvoriť model, ktorý by bol dostatočne univerzálny natoľko, aby vedel určiť počet vozidiel na fotografii v akomkoľvek prostredí (čas, počasie, poveternostné podmienky) a v čo najkratšom čase. V súčasnosti model dokáže predikovať správny počet vozidiel na výrezu na testovacích dátach s presnosťou 87% a s pripustením chyby prvého rádu na 95%. Primárnym cieľom tejto práce je riešenie tohto problému v reálnom čase. Jedná sa klasifikáciu do 7 tried (0-6 vozidiel). Toto riešenie by mohlo byť zaujímavé hlavne pre statické kamery na netypických miestach (napr. bočný pohľad), prípadne je pre ne dôležité snímanie určitých špeciálnych oblastí parkovísk.

![]()
Šimon Sedláček
Voice Activity Detection, Recurrent Neural Networks, Speaker Verification
Zpracování dat (obraz, zvuk, text apod.)
This work aims to implement, test, and evaluate a speaker-conditioned voice activity detection method proposed by [1], originally called "Personal VAD". The method builds upon an LSTM based approach to voice activity detection and its purpose is to introduce a system that can reliably detect speech of a target speaker, while retaining the typical characteristics of a VAD system, mainly in terms of small model size, low latency, and low necessary computational resources. The system is trained to distinguish between three classes: non-speech, target speaker speech, and non-target speaker speech. For this purpose, the method utilizes speaker embeddings as a part of the input feature vector to represent the target speaker. Some of the more heavyweight personal VAD variants also make use of speaker verification scores issued to each frame based on the target embedding, resulting in a more robust system. In addition to the one scoring method presented in the original paper, two other scoring approaches are introduced, both outperforming the baseline method and improving the system's performance even for acoustically challenging conditions.

![]()
Jan Grossmann
Information system, Data exploration, Geographical visualization
Informační systémy
The goal of this project is to create an information system for the visualization of geographical data. The main idea is to allow users to visualize their own geographical data, which they can import either from plain text files or directly attach their own database system as a source of data and make use of the data in real-time. By providing the necessary information like the type of database management system and credentials, the back-end of the information system will be able to connect, read or build up the schema of the database including all of the stored tables, objects, and its dimensions. Then the user will choose the proper form of data through the graphical user interface with zero need for programming knowledge. These data will be used to create the visualizations, using an existing application for visualization of geographical data named Geovisto. Created visualizations could be also shared easily, by providing a specific link that will show the interactive result, allowing the user to embed the view into his personal webpage. This paper presents a new web information system that will act as a point of contact between users, geographical data, and visualizations.
![]()
Marek Tamaškovič
Blockchain, Proof-of-Stake, Anonymity
Bezpečnost Počítačové sítě
In this work, we summarized research in the state-of-the-art Proof-of-Stake protocols like Algorand, Tendermint, and LaKSA. We analyzed and summarized their features and issues. Based on the included research we propose a new PoS protocol that mitigates the found issues.
![]()
Petr Rusiňák
IoT, Secure provisioning, IoT device provisioning
Bezpečnost
With the role of IoT devices being more important than ever before, many large-scale applications of IoT devices are emerging. However, setting up a large number of IoT devices is time-consuming, as in most cases, it involves taking each IoT device individually, reflashing its firmware based on the device's use-case, and reconfiguring the device's settings to include the correct Wi-Fi credentials as well as other device-specific settings based on the use-case application. The aim of this paper is to create a zero-touch provisioning protocol that will configure the IoT device on its first boot automatically in a secure manner. At this stage of development, the work focuses on secure provisioning of Wi-Fi credentials, as the credentials cannot be shared with the device manufacturer for security reasons, and they cannot be obtained by the application code as the device has no internet connectivity. The protocol uses a dedicated configurator device to obtain the credentials, with a challenge-response authentication in place to verify the new device is authorized to obtain these credentials.
![]()
Jana Gregorová
Automatic Score Evaluation for Bullseye Shooting, Computer Vision in Sports Shooting, Background Subtraction, Template Matching, Image Stabilization, Cross-correlation of Two 2D Arrays
Zpracování dat (obraz, zvuk, text apod.)
Bullseye shooting is a shooting sports discipline where the shooter is standing in one place and shooting at a static paper target. The shooter’s goal is to land as many hits in the centre of the target as possible. The distance between the shooter and the target usually ranges from 10 m to 300 m. That way, while shooting, the shooter is unable to see where exactly their hits land unless some kind of auxiliary equipment is used. To calculate the score, all shooting needs to be stopped as the shooter walks right into the field to see their target up close. For a new round, the shooter either has to change the target for a new one or cover target hits up with cover up patches. The goal of this work is to find a solution to calculate shooter’s score automatically. One of the possible approaches to this problem is taking a video of the target and processing it, so that new hits in the target can be detected and their score calculated. The resulting image will then be shown to the shooter on a screen near them. The result of this paper is a commercial distribution-ready solution both for individual shooters and commercial shooting ranges. The solution consists of a camera setup and an application which displays the video from camera and evaluates the shooter’s score using computer vision. The solution brings significant improvements in terms of shooter’s comfort and bullseye shooting training effectiveness. It is an innovative equipment not only for skilled shooters, but also for beginner shooters.

![]()
Samuel Dudík
WebKitGTK, adblock, rozšírenie, prehliadač
Webové technologie
Cieľom práce je vytvoriť rozšírenie pre prehliadače založené na technológii WebKitGTK, ktoré užívateľom umožní pohodlné blokovanie reklám, sledovacích prvkov a rôznych nežiadúcich prvkov. Samotné rozšírenie je implementované v jazyku C. Na pozadí komunikuje so serverom napísanom v jazyku Rust, ktorý rozhoduje, či konkrétnu požiadavku zablokovať alebo povoliť. Server využíva knižnicu adblock-rust, ktorá bola pôvodne vytvorená pre potreby prehliadača Brave. Komunikácia medzi serverom a klientom prebieha pomocou mechanizmu Unix domain socket. Výsledkom práce je BlocKit -- plnohodnotné rozšírenie určené na filtrovanie obsahu podporujúce okrem sieťového aj kozmetické filtrovanie. Súčasťou je i minimalistické GUI na jednoduchú konfiguráciu a interakciu s rozšírením.

![]()
Jakub Pojsl
Meal planner, Meal plan generator, Web application, Nutrition monitoring, Django, User interface
Uživatelská rozhraní Webové technologie
The aim of this work is design and implementation of a web-based application that helps its users to improve their eating habits and potentially contributes to the reduction of food waste. The app allows users to easily plan their meals, monitor nutrition in their diet, and automatically generate personalized meal plans according to their body predispositions, goals, and lifestyle. Most attention was given to the design and testing of a user interface that would allow users to effectively manage their meal plans.

![]()
Richard Stehlik
ESP32, ESP-IDF, Wi-Fi attack, PMKID, WPA handshake, handshake sniffer, penetration tool
Bezpečnost
This work explores possibilities of Espressif's ESP32 SoCs in combination with its official development framework ESP-IDF in terms of implementing well-known Wi-Fi attacks on them. Using ESP32 for such attacks may allow attackers to scale their malicious intentions more easily and cut cost and complexities of Wi-Fi attack executions to minimum. Being low powered device also opens ways to minimize size of necessary hardware for Wi-Fi attacks and can easily operate on battery while maintaining a low weight. Proposed solution presented in this work covers attacks on WPA/WPA2 authentication and their variations like station deauthentication, WPS PIN brute-force attack or PMKID capture. An universal Wi-Fi penetration tool for ESP32 was introduced, that provides easy way to implement new attacks and their variants in the future. It shows how these attacks can be implemented purely by using ESP-IDF's public API or by bypassing closed source Wi-Fi Stack Libraries that have incorporated protection against misusing ESP32 for sending forged frames. The outcome supports the need to mitigate some vulnerabilities in currently widely used Wi-Fi security features and give them more attention with higher priority.

![]()
Šimon Stupinský
automated synthesis, probabilistic programs, Markov models, model checking
Testování, analýza a verifikace
Probabilistic programs play a key role in various engineering domains, including computer networks, embedded systems, power management policies, or software product lines. This paper presents PAYNT, a tool for the automatic synthesis of probabilistic programs satisfying the given specification. It supports the synthesis of finite-state probabilistic programs representing a finite family of candidate programs. PAYNT provides a novel integrated approach for probabilistic synthesis developed on the principles of abstraction refinement (AR) and counterexample-guided inductive synthesis (CEGIS) methods. PAYNT is able to efficiently synthesise the topology of the program as well as continuous parameters affecting the transition probabilities – this is a unique feature. Existing tools for topology synthesis implement only naive approaches and thus typically do not scale to practically relevant synthesis problems. Tools leveraging search-based techniques can handle both synthesis problems, but they do not ensure the complete exploration of the design space. For challenging synthesis problems, PAYNT is able to significantly decreases the run-time from days to minutes while ensuring the completeness of the synthesis process. We demonstrate the usefulness and performance of PAYNT on a wide range of benchmarks from different application domains. Our tool paper presenting PAYNT has been recently accepted at CAV’21, an A* conference.

![]()
Michal Horký
regular expression matching, bounded repetition, ReDoS, counting automata, RE2
Zpracování dat (obraz, zvuk, text apod.)
Regular expression (regex) matching has an irreplaceable role in software development. The speed of the matching is crucial since it can have a significant impact on the overall usability of the software. However, standard approaches for regular expression (regex) matching suffer from high complexity computation for some kinds of regexes. This makes them vulnerable to attacks based on high complexity evaluation of regexes (so-called ReDoS attacks). Regexes with counting operators, which often occurs in practice, are one of such kind. Succinct representation and fast matching of such regexes can be archived by using a novel counting set automaton. We present a C++ implementation of a matching algorithm based on the counting set automaton. The implementation is done within the RE2 library, which is a fast state-of-the-art regular expression matcher. The implementation within an existing library has the advantage of using its already implemented and optimized parts. We hope that using such parts helps our implementation to be even faster and outperforms some of the state-of-the-art matchers in matching regexes with counting operators while preserving the advantages of the original algorithm for other kinds of regexes.

![]()
Vladimir Jerabek
Monitorování sítě, Peer-to-Peer, Bitcoin, Kryptoměny, Analýza dat
Počítačové sítě
Cílem této práce je vytvořit platformu, která bude shromažďovat relevantní informace o aktivních uzlech v peer-to-peer síti Bitcoin. Díky monitorování chování jednotlivých uzlů v síti, jsem schopen sbírat důležité data pro podrobnější analýzu. Implementované řešení využívá nemodifikovaného Bitcoin Core klienta, a nabízí jednoduchou škálovatelnost díky modulární architektuře, která je dosažena za pomoci Docker kontejnerizace. Platforma poskytuje i jednoduchou vizualizaci nashromážděných dat. Součástí této práce je také analýza nashromážděných dat z dvouměsíčního běhu platformy BiNMon. Tato platforma v rukou vědců bude představovat relevantní a autentický zdroj informací o kryptoměně Bitcoin. V neposlední řadě může tato práce sloužit i jako zdroj inspirace pro ostatní vývojáře, kteří chtějí vytvořit podobný nástroj na shromažďování a analýzu velkého množství dat například z dalších kryptoměn.
![]()
Petr Buchal
neuronová síť, rozpoznání textu, self-training, neanotovaná data, jazykový model
Robotika a umělá inteligence
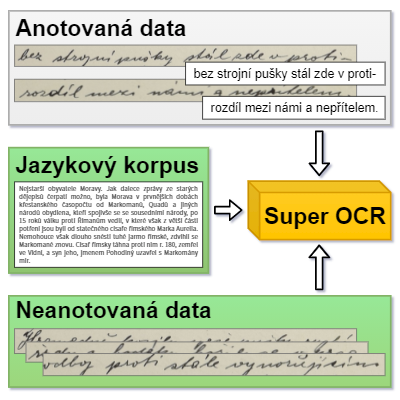
Vytvoření kvalitního systému rozpoznání textu (OCR) vyžaduje velké množství anotovaných dat. Získání, potažmo vytvoření anotací je nákladný proces. Tato práce se zabývá využitím neanotovaných dat pro trénování OCR neuronové sítě. Navržená metoda využívající neanotovaná data spadá do kategorie self-training algoritmů. Nejprve je na omezeném množství anotovaných dat natrénován počáteční model neuronové sítě. Ten je následně spolu s jazykovým modelem použit k vygenerování několika nejpravděpodobnějších variant pseudo-štítků neanotovaných dat. Takto strojově anotovaná data jsou smíchána s trénovacími daty, která byla použita k vytvoření počátečního modelu a následně jsou využita k natrénování cílového modelu. Na ručně psaném ICFHR 2014 Bentham datasetu dosahuje nejlepší takto trénovaný model 1.99 % CER, což je relativní zlepšení o 23 % oproti počátečnímu modelu trénovaném pouze na anotovaných datech. Za pomocí navržené metody lze zvýšit úspěšnost OCR pomocí neanotovaných dat.

![]()
Petr Kašpar
Heat map, Color blindness, Geovisualization
Uživatelská rozhraní
Data visualization on a map is a tool which is being used in fields such as industry, political science, education and, now more than ever, epidemiology. Heat map is a type of geospatial visualization which displays intensity of observed phenomenon using color spectrum. However, people with visual impairment, commonly known as color blindness, are being limited in usage of these tools as colors as perceived by them are at best misleading, and at worse totally indistinguishable from each other. This makes it hard to even read displayed data, while making it practically impossible to create a visualization of their while being sure that they picked the right color spectrum. To address this issue I have extended an existing solution -- geovisualization application Geovisto with heat map layer which provides color schemes for people with most common forms of color blindness. By using the right scheme a person with color blindness can be sure that they are seeing true colors which are not being distorted by their specific type of impairment. It's then possible to switch to generally used blue-green-red color spectrum and publish it with confidence that people without any form of color blindness are seeing the right result. I have created a set of color schemes for users with dichromacy using tools which try to emulate color perception for color blind people.
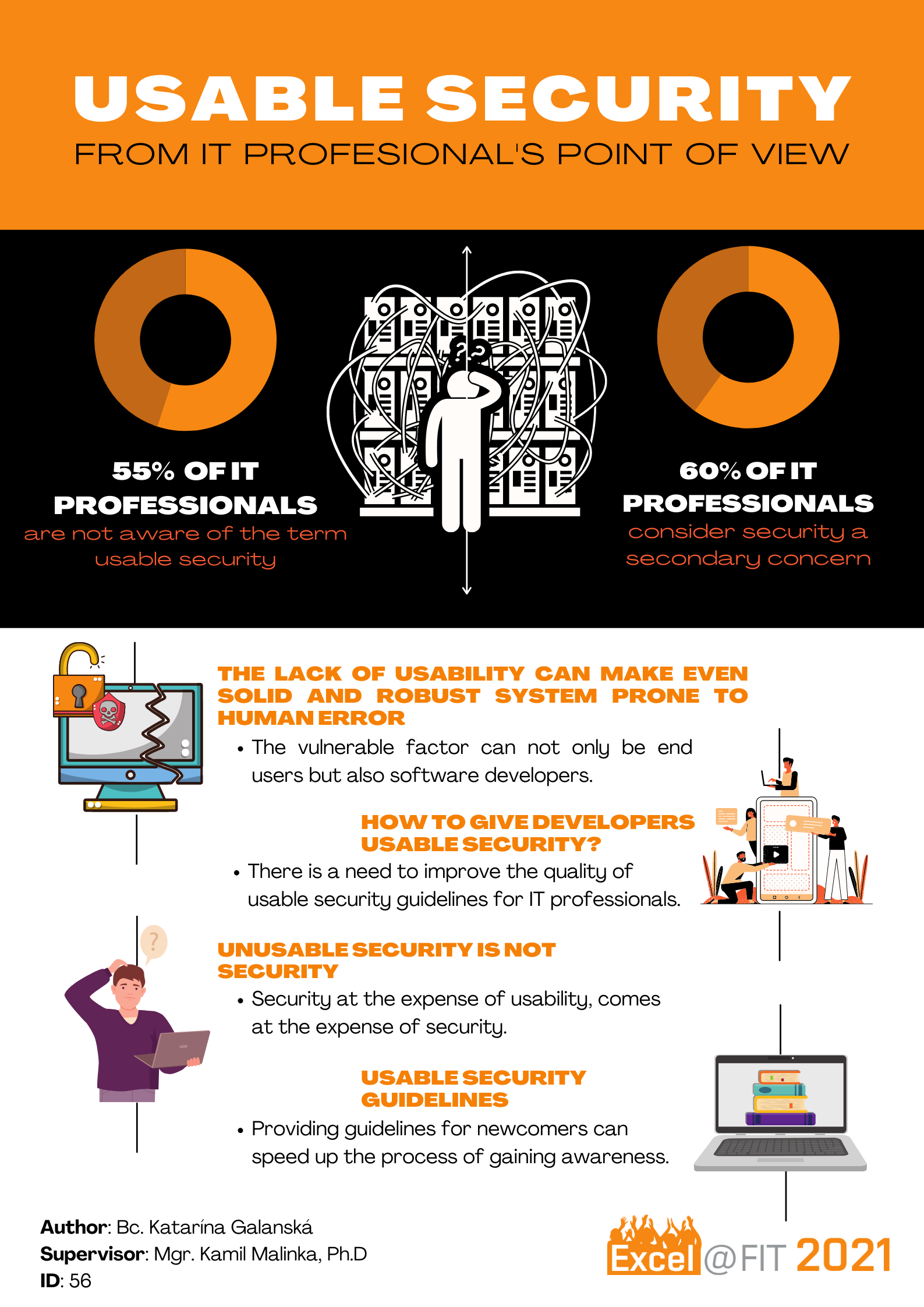
![]()
Katarína Galanská
usable security, usability evaluation, authentication, encryption, digital certificates, privacy
Bezpečnost
Balancing the security and usability has always been a challenge. Despite the importance of secure software, the security guidelines and standards are often too complicated, prone to error or time consuming. This non-equilibrium initiated the creation of the term usable security. For years it has been a common research problem. While the software should be developed with usability considerations of end users, security standards and guidelines used by IT professionals are not often given enough attention from the usability perspective. As the experts in the IT field are expected to have a higher level of knowledge, they often face very complex areas when trying to be compliant to particular security standard or follow specific guideline. This work presents the survey in the field of usable security, the aim of which was to evaluate the current awareness of the usable security across the people working in the software development. It discusses problems associated with the balance of the security and usability and devotes to design and implement an educational tool helping the newcomers in the IT field with making systems secure and usable. The aim is to introduce better understanding in certain areas of usable security, namely authentication, privacy, encryption and digital certificates.
![]()
Dominik Harmim
Facebook Infer, Static Analysis, Abstract Interpretation, Atomicity Violation, Contracts for Concurrency, Concurrent Programs, Program Analysis, Atomicity, Atomer
Testování, analýza a verifikace
Atomer is a static analyser based on the idea that if some sequences of functions of a multi-threaded program are executed under locks in some runs, likely, they are always intended to execute atomically. Atomer thus strives to look for such sequences and then detects for which of them the atomicity may be broken in some other program runs. The first version of Atomer was proposed within the BSc thesis of the author of this paper and implemented as a plugin of the Facebook Infer framework. In this paper, a new and significantly improved version of Atomer is proposed. The improvements aim at both increasing scalability as well as precision. Moreover, support for several initially not supported programming features has been added (including, e.g., the possibility of analysing C++ and Java programs or support for re-entrant locks or lock guards). Through a number of experiments (including experiments with real-life code and real-life bugs), it is shown that the new version of Atomer is indeed much more general, scalable, and precise.

![]()
Pavel Dohnalík
Mobilní aplikace, SmartWatch, Flutter, iOS, Android, WearOS, 5G, REST, Java
Uživatelská rozhraní
Cílem této práce je navrhnout a realizovat novou aplikaci na chytré hodinky pro podporu sportovních tréninků a malých závodů ve sportovních klubech. Výsledná práce zahrnuje multiplatformní multijazyčnou mobilní aplikaci pro Android a iOS, aplikaci na chytré hodinky s Wear OS a webovou aplikaci. Aplikace pro chytré hodinky má obsahovat snadné párování na aplikaci v telefonu. Webová aplikace slouží k vytváření závodních tras. Pomocí hodinek jde přesně změřit sportovní aktivitu, která jde následně na telefonu analyzovat. Na telefonu bude probíhat dopočet zpřesnění polohy k průjezdové bráně a času průjezdu. Stejná funkce měření sportovní aktivity bude k dispozici v telefonu. Závodník bude dostávat informace o své pozici v závodě a to pomocí jednoduchého uživatelského rozhraní. K vytvoření mobilní multiplatfomní aplikace, aplikace pro chytré hodinky a webové aplikace je použitý framework Flutter 2.0 spolu s jazykem Dart. Pro serverovou část je využívána Java Spring v kombinaci s MySQL databází. Celá serverová část je nasazována v dockeru a komunikuje s mobilními zařízeními pomocí REST API. Výsledkem je serverová aplikace, mobilní multiplatfomní aplikace, aplikace na chytré hodinky a webová aplikace.
Příspěvky na Excel@FIT procházejí recenzním řízením, ale nejsou považovány za finální publikaci výsledku. Příspěvek na Excel@FIT se nevylučuje s následnou publikací na vědecké či odborné konferenci nebo v časopise. Autorům kvalitních příspěvků na Excel@FIT a jejich vedoucím se naopak taková publikace doporučuje.
Submissions at Excel@FIT go through a reviewing proces, but they are not considered to be final publications of the result. Contributions presented at Excel@FIT do not exclude further publication at a scientific or professional conference or in a journals. Contrary to that, authors of high-quality contributions at Excel@FIT and their supervisors are encouraged to prepare such a contribution.