
![]()
![]()
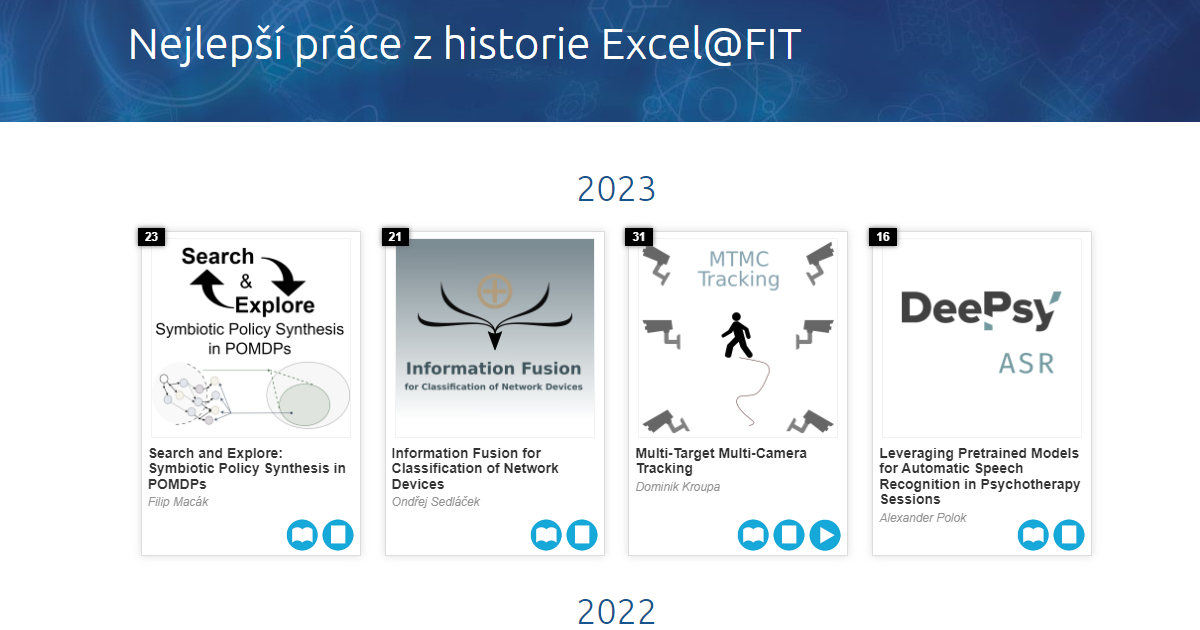
Filip Macák
POMDP, FSC, Policy synthesis
Testování, analýza a verifikace systémů

![]()
![]()
Ondřej Sedláček
Network Monitoring, Information Fusion, Interpretable Classification, Dempster-Shafer Theory
Hardware a počítačové sítě

![]()
![]()
![]()
Dominik Kroupa
object detection, object tracking, object re-identification, multi-target multi-camera tracking
Zpracování obrazu, zvuku a videa

![]()
![]()
Alexander Polok
automatic speech recognition , language modeling, self-supervised learning, end-to-end models, psychotherapy session analysis
Strojové učení a neuronové sítě

![]()
![]()
Samuel Repka
Photometric stereo, Scanning electron microscope, 4-segment BSE detector
Zpracování dat (obraz, zvuk, text apod.)
While scanning electron microscopes (SEM) provide an extraordinary spectrum of information about the specimens, they do not answer a few fundamental questions. How high? How deep? This paper aims to explore possibilities of topography reconstruction of microscopic samples, as well as to attempt to solve the task using tools already available on conventional scanning electron microscopes. The proposed solution uses images from a four-segment backscattered electrons detector as an input to the photometric stereo algorithm. This algorithm exploits the fact, that the brightness of the image point is dependent on the inclination of the sample surface. Reflectance maps are used to estimate the inclination in each pixel, creating a map of normal vectors. The map is then used for topography reconstruction. A novel technique for reflectance map estimation is proposed. This method is applied to tin samples to remove the sample’s atomic number effects. Solution evaluation was not yet performed. The fact that all data are acquired simultaneously allows for fast reconstruction. Usage of already available and widespread tools eliminate a need for specialized equipment such as Atomic Force Microscopes.
![]()
![]()
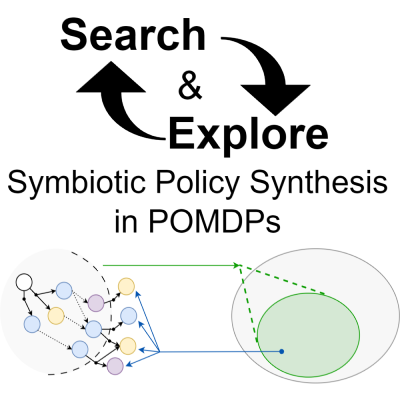
Barbora Šmahlíková
Büchi Automata, Elevator Automata, Büchi Complementation
Testování, analýza a verifikace
Büchi automata complementation is an important operation for decision procedures of some logics, proving termination of programs, or model checking of temporal properties. Due to the high space complexity of Büchi automata complementation, it is necessary to look for some optimizations reducing the size of generated state space for good performance in practice. In this paper, we identify elevator automata, a class of Büchi automata, which often occurs in practice. Thanks to their specific structure, we are able to reduce the bound on the maximum rank of states in each strongly connected component, which is one of the main causes of a state space blow-up in rank-based complementation. We compare these techniques, implemented as an extension of the tool Ranker, with other state-of-the-art tools and show that with these optimizations, rank-based complementation is competitive to other complementation approaches and can give better results on a large set of benchmarks.

![]()
![]()
Son Hai Nguyen
neural solver, Helmholtz equation, graph neural network, transcranial ultrasound, PDE
Modelování a simulace Robotika a umělá inteligence
Neural solvers have been increasingly explored with the aim of replacing computationally expensive conventional numerical methods for solving PDEs. This work focuses on solving the time-independent Helmholtz equation for transcranial ultrasound therapy. Most of the popular methods for modeling physics systems are based on U-net. However, convolutional neural networks require the data to be sampled on a regular grid. In order to try to lift this restriction, we propose an iterative solver based on graph neural networks. Unlike Physics-informed neural networks, our model needs to be trained only once, and only a forward pass is required to obtain a new solution given input parameters. The model is trained using supervised learning, where the reference results are computed using the traditional solver k-Wave. Our results show the model’s unroll stability despite being trained with only 8 unroll iterations. Despite the model being trained on the data with a single source, it can predict wavefields with multiple sources and generalize to much larger computational domains. Our model can produce a prediction for sub-pixel points with higher accuracy than linear interpolation.

![]()
![]()
Petr Kohout
bioinformatika, proteinové inženýrstvı́, molekulárnı́ dynamika, tunely, dokovánı́
Bioinformatika
Tato práce se zabývá analýzou proteinových struktur. Cílem je vytvořit Caver Web 2.0 - novou verzi webové aplikace, která začlení další vědecké nástroje a uživatelům umožní projít komplikovaný pracovní protokol za poskytnutí relevantních výsledků bez nutnosti hlubší znalosti integrovaných nástrojů. Vše bude zprostředkováno prostřednictvı́m jednoduchého a interaktivnı́ho uživatelského rozhranı́. Aplikace rozšiřuje původnı́ aplikaci Caver Web 1.0 o nové vlastnosti. Caver Web 1.0 je webový server vhodný pro identifikaci proteinových tunelů a kanálů, pro které umožňuje spustit analýzy transportu ligandů. Program se vyznačuje intuitivnı́m a uživatelsky přı́větivým rozhranı́m s minimem požadovaných vstupů od uživatele. Server je vhodný i pro výzkumnı́ky bez pokročilých bioinformatických nebo technických znalostı́. Jeho současná verze je ve vědecké komunitě dobře zavedená a velmi využı́vaná (35 000 dokončených výpočtů během dvou let provozu). Nejvýznamnějšı́m omezenı́m současné verze je možnost analyzovat pouze statickou strukturu, což často poskytuje neúplný biologický obraz. Proto jsme se rozhodli nástroj rozšı́řit o výpočet molekulárnı́ch dynamik, které poskytnou ucelený obraz na proměny proteinových struktur. Touto funkcı́ se Caver Web 2.0 stane prvnı́m webovým nástrojem, který bude poskytovat analýzu tunelů bez nutnosti ručnı́ch výpočtů molekulárnı́ch dynamik. Grafické uživatelské rozhranı́ bude navrženo speciálně pro vědeckou komunitu s podporou jednoduchého exportu. Nástroj bude zdarma k dispozici celé vědecké komunitě.
![]()
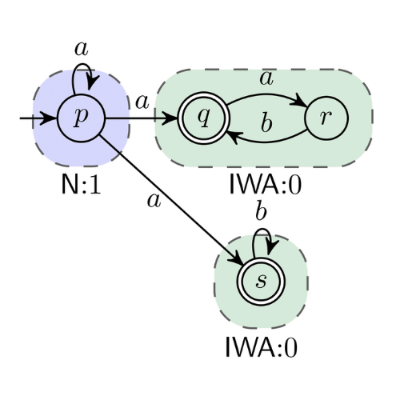
Filip Kočica
sklad, optimalizace, simulace, generátor, objednávka, produkt, pickování, evoluce
Robotika a umělá inteligence
Tato práce řeší problematiku alokace produktů do lokací ve skladu za pomoci moderních meta-heuristických přístupů v kombinaci s realistickou simulací skladu. Práce poskytuje grafický nástroj umožňující sestavení modelu skladu, generování syntetických zákaznických objednávek, optimalizaci alokace produktů za pomoci kombinace state of the art technik, simulátor vytvořeného modelu skladu a nakonec nástroj pro hledání nejkratší cesty objednávky skrze sklad. Práce také uvádí porovnání různých přístupů a experimenty s vytvořenými nástroji. Podařilo se optimalizovat propustnost experimentálního skladu na téměř dvojnásobek (~57%). Přínosem této práce je možnost vytvoření modelu plánovaného či již existujícího skladu a jeho simulace i optimalizace, což může značně zvýšit propustnost skladu a pomoci detekovat a odstranit vytížená místa. To může vést k ušetření zdrojů či pomáhat v plánování. Dále tato práce přináší nový způsob optimalizace skladu a nové optimalizační kritérium.
![]()
Jana Gregorová
Automatic Score Evaluation for Bullseye Shooting, Computer Vision in Sports Shooting, Background Subtraction, Template Matching, Image Stabilization, Cross-correlation of Two 2D Arrays
Zpracování dat (obraz, zvuk, text apod.)
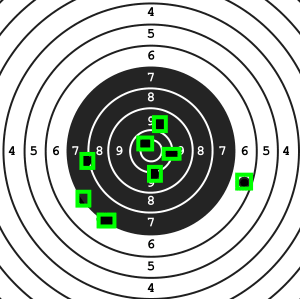
Bullseye shooting is a shooting sports discipline where the shooter is standing in one place and shooting at a static paper target. The shooter’s goal is to land as many hits in the centre of the target as possible. The distance between the shooter and the target usually ranges from 10 m to 300 m. That way, while shooting, the shooter is unable to see where exactly their hits land unless some kind of auxiliary equipment is used. To calculate the score, all shooting needs to be stopped as the shooter walks right into the field to see their target up close. For a new round, the shooter either has to change the target for a new one or cover target hits up with cover up patches. The goal of this work is to find a solution to calculate shooter’s score automatically. One of the possible approaches to this problem is taking a video of the target and processing it, so that new hits in the target can be detected and their score calculated. The resulting image will then be shown to the shooter on a screen near them. The result of this paper is a commercial distribution-ready solution both for individual shooters and commercial shooting ranges. The solution consists of a camera setup and an application which displays the video from camera and evaluates the shooter’s score using computer vision. The solution brings significant improvements in terms of shooter’s comfort and bullseye shooting training effectiveness. It is an innovative equipment not only for skilled shooters, but also for beginner shooters.
![]()
Jan Zavřel
EIGRP, Simulation, Routing, OMNeT++
Modelování a simulace Počítačové sítě
This paper deals with the implementation and the evaluation of a simulation model of a modern dynamic routing protocol designed by Cisco Systems, Inc. called Enhanced Interior Gateway Routing Protocol (EIGRP) in a discrete simulator OMNeT++ implemented in C++. The resulting simulation model can be used to conduct various experiments which allow network designers and alike to explore the protocol's behavior in different situations inside a safe discrete environment. In order to produce a trustworthy simulation course, the protocol model must be as accurate as possible to the real implementation and thoroughly tested. This paper provides a basic overview of both protocol EIGRP and simulator OMNeT++. It also discusses the state of the model before and after the integration into a newer version of the INET framework, showcases improvements, and outlines the testing methodology.

![]()
Šimon Stupinský
automated synthesis, probabilistic programs, Markov models, model checking
Testování, analýza a verifikace
Probabilistic programs play a key role in various engineering domains, including computer networks, embedded systems, power management policies, or software product lines. This paper presents PAYNT, a tool for the automatic synthesis of probabilistic programs satisfying the given specification. It supports the synthesis of finite-state probabilistic programs representing a finite family of candidate programs. PAYNT provides a novel integrated approach for probabilistic synthesis developed on the principles of abstraction refinement (AR) and counterexample-guided inductive synthesis (CEGIS) methods. PAYNT is able to efficiently synthesise the topology of the program as well as continuous parameters affecting the transition probabilities – this is a unique feature. Existing tools for topology synthesis implement only naive approaches and thus typically do not scale to practically relevant synthesis problems. Tools leveraging search-based techniques can handle both synthesis problems, but they do not ensure the complete exploration of the design space. For challenging synthesis problems, PAYNT is able to significantly decreases the run-time from days to minutes while ensuring the completeness of the synthesis process. We demonstrate the usefulness and performance of PAYNT on a wide range of benchmarks from different application domains. Our tool paper presenting PAYNT has been recently accepted at CAV’21, an A* conference.

![]()
![]()
Monika Mužikovská
ANaConDA, Dynamická analýza, Paralelní chyby, Víceprocesové programy
Testování, analýza a verifikace
Dynamická analýza se s úspěchem využívá pro detekci chyb ve vícevláknových programech. Algoritmy, které byly za tímto účelem navrženy, jsou ale často využitelné i pro víceprocesové programy. Žádný ze známých nástrojů pro dynamickou analýzu ale monitorování procesů nepodporuje. Cílem této práce bylo rozšířit nástroj ANaConDA o analýzu a monitorování víceprocesových programů. Výsledkem je implementace rozšíření, které za vývojáře analyzátorů řeší problémy spojené s oddělenými adresovými prostory a synchronizací pomocí semaforů. Rozšíření bylo využito pro úpravu analyzátoru AtomRace pro detekci časově závislých chyb nad daty ve víceprocesových programech a použito na experimenty se studentskými projekty z předmětu Operační systémy. Výsledky experimentů ukázaly, že se nástroj ANaConDA může stát vítaným pomocníkem při implementaci nejen víceprocesových projektů.

![]()
![]()
Michal Piňos
Neuroevoluce, Neuronové sítě, Evoluční výpočetní techniky
Robotika a umělá inteligence
Cı́lem této práce je návrh a implementace programu pro automatizovaný návrh konvolučnı́ch neuronových sı́tı́ (CNN) s využitı́m evolučnı́ch výpočetnı́ch technik. Z praktického hlediska tento přı́stup redukuje potřebu lidského faktoru při tvorbě CNN, a tak eliminuje zdlouhavý a namáhavý proces návrhu. Tato práce využı́vá speciálnı́ formu genetického programovánı́ nazývanou kartézské genetické programovánı́, které pro zakódovánı́ řešeného problému využı́vá grafovou reprezentaci. Tato technika umožňuje uživateli parametrizovat proces hledánı́ CNN, a tak se zaměřit na architektury zajı́mavé z pohledu použitých výpočetnı́ch jednotek, přesnosti či počtu parametrů. Navrhovaný přı́stup byl otestován na standardizované datové sadě CIFAR-10, která je často využı́vána výzkumnı́ky pro srovnánı́ výkonnosti jejich CNN. Prvotnı́ experimenty ukázaly, že vytvořená implementace (využı́vajı́cı́ GPU akceleraci) je schopna vytvořit či vylepšit přesnost CNN. Výsledkem experimentů, kdy bylo pro trénovánı́ k dispozici pouze několik epoch, byla řešenı́ s přesnostı́ 64.5 % a počtem parametrů 146K při využitı́ základnı́ch vrstev a řešenı́ s přesnostı́ 74.5 % s počtem parametrů 475K při využitı́ reziduálnı́ch vrstev. Záměrem těchto experimentů bylo dokázat funkčnost implementovaného programu a proof-of-concept navržené metody.
![]()
![]()
Martin Gaňo
Neural networks, Optimization, Machine learning
Robotika a umělá inteligence Zpracování dat (obraz, zvuk, text apod.)
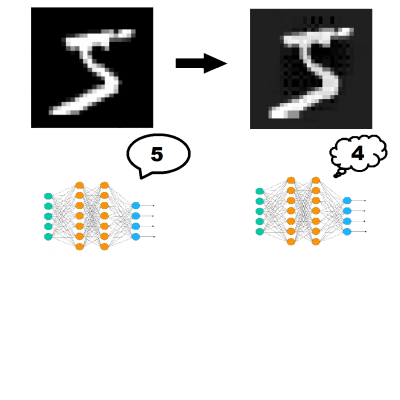
The main goal of this work is to design and implement the framework that yields robust neural network model against whatever adversarial attack, while result models accuracy is not significantly lower comparing to naturally trained model. Our approach is to minimize maximization the loss function of the target model. Related work and our experiments lead us to the usage of Projected gradient descent method as a reference attack, therefore, we train against data generated by PGD. As a result, using the framework we can reach accuracy more than 90% against sophisticated adversarial attacks on MNIST dataset. The greatest contribution of this work is an implementation of adversarial attacks and defences against them because there misses any public implementation.

![]()
![]()
Drahomír Dlabaja
Light field, Lossy compression, JPEG, Transform coding, Plenoptic representation, Quality assessment
Zpracování dat (obraz, zvuk, text apod.)
This paper proposes a light field image encoding solution based on four-dimensional discrete cosine transform and quantization. The solution is an extension to JPEG baseline compression. A light field image is interpreted and encoded as a four-dimensional volume to exploit both intra and inter view correlation. Solutions to 4D quantization and block traversal are introduced in this paper. The experiments compare the performance of the proposed solution against the compression of individual image views with JPEG and HEVC intra in terms of PSNR. Obtained results show that the proposed solution outperforms the reference encoders for light images with a low average disparity between views, therefore is suitable for images taken by lenslet based light field camera and images synthetically generated.
![]()
![]()
Dominik Harmim, Vladimír Marcin, Ondřej Pavela
Facebook Infer, Static Analysis, Abstract Interpretation, Atomicity Violation, Concurrent Programs, Performance, Worst-Case Cost, Deadlock
Testování, analýza a verifikace
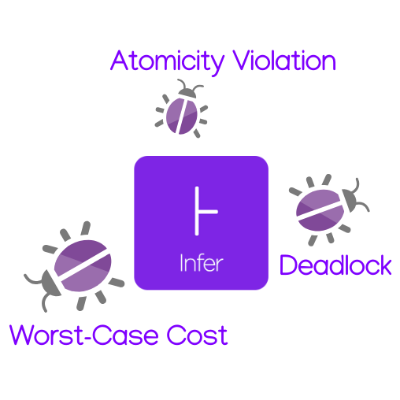
Static analysis has nowadays become one of the most popular ways of catching bugs early in the modern software. However, reasonably precise static analyses do still often have problems with scaling to larger codebases. And efficient static analysers, such as Coverity or Code Sonar, are often proprietary and difficult to openly evaluate or extend. Facebook Infer offers a static analysis framework that is open source, extendable, and promoting efficient modular and incremental analysis. In this work, we propose three inter-procedural analysers extending the capabilities of Facebook Infer: Looper (a resource bounds analyser), L2D2 (a low-level deadlock detector), and Atomer (an atomicity violation analyser). We evaluated our analysers on both smaller hand-crafted examples as well as publicly available benchmarks derived from real-life low-level programs and obtained encouraging results. In particular, L2D2 attained 100 % detection rate and 11 % false positive rate on an extensive benchmark of hundreds of functions and millions of lines of code.

![]()
![]()
Josef Jon
neural machine translation, context, transformer, document level translation
Zpracování dat (obraz, zvuk, text apod.)
This works explores means of utilizing extra-sentential context in neural machine translation (NMT). Traditionally, NMT systems translate one source sentence to one target sentence without any notion of surrounding text. This is clearly insufficient and different from how humans translate text. For many high resource language pairs, NMT systems output is nowadays indistinguishable from human translations under certain (strict) conditions. One of the conditions is that evaluators see the sentences separately. When evaluating whole documents, even the best NMT systems still fall short of human translations. This motivates the research of employing document context in NMT, since there might not be much more space left to improve translations on sentence level, at least for high resource languages and domains. This work sumarizes recent state-of-the art approaches, implements them, evaluates them both in terms of general translation quality and on specific context related phenomena and analyzes their shortcomings. Additionaly, context phenomena test set for English to Czech translation was created to enable further comparison and analysis.
![]()
![]()
Jiří Pavela, Šimon Stupinský
Performance, Continuous integration, Automated degradation detection, Difference analysis, Clusterization, Regression analysis
Testování, analýza a verifikace
Current tools for project performance analysis focus mostly on detecting selected performance bugs in the source code. Although being useful, results of such tools cannot provide evaluation of project’s overall performance which is often crucial for development of large applications. Building on our previous works, we aim to provide a solution to a long term monitoring of performance changes using the tool chain of performance data collection, regression analysis, and subsequent automated detection of performance changes performed. We evaluated our solution on series of artificial examples and we were able to detect about 85% of performance changes across different performance models and errors, and estimate their severity (e.g. constant, linear, etc). The proposed solution allows user to deploy new method of code review—possibly integrated into continuous integration—and reveal performance changes introduced by new versions of code in early development.
![]()
![]()
Ivan Ševčík
Databáza, Vyhľadávanie vzorov, Grafový izomorfizmus
Databáze a data-mining
V tomto článku je predstavený spôsob, pomocou ktorého je možné vyhľadávať zadaný vzor ako podštruktúru v databázach chemických látok obsahujúcich desiatky miliónov záznamov. Jedná sa o výpočetne náročný problém, ktorý je potrebné riešiť na niekoľkých úrovniach. Metóda prezentovaná v tomto článku využíva kombináciu topologických indexov, tzv. molekulárnych odtlačkov, a rýchleho algoritmu pre hľadanie izomorfného podgrafu. Práca porovnáva niekoľko algoritmov, ako aj spôsobov uloženia molekúl v systéme. Najlepším riešením sa ukázalo byť použitie algoritmu zvaného RI v kombinácii s uložením serializovaných dát do databázy MongoDB. Riešenie umožňuje užívateľom vyhľadávať v databázach v reálnom čase, do niekoľkých sekúnd. Cieľom tohto článku je oboznámiť čitateľa s problematikou vyhľadávania v chemických databázach a ako je možné vytvoriť takýto systém pre vyhľadávanie s ohľadom na súčasný výskum. Výsledky a myšlienky práce by mohli byť využité v príbuzných oblastiach vyžadujúcich vyhľadávanie vzorov v databázach, ako je napríklad počítačové videnie.

![]()
![]()
Jan Kubálek
DMA, DPDK, FPGA, PCI-Express
Počítačová architektura a vestavěné systémy
Devices in computer networks, which are used for network management, require a high-speed processing of a large amounts of data for analysis. For a device to enable the monitoring of a network with high data traffic, its network interface card needs to be capable of transferring received data to RAM at sufficient speed. My project deals with the design, implementation, and testing of a new module for an FPGA chip on a network interface card, which will carry out these transfers. The design aims to achieve a high throughput of up to 200 Gb/s for the transfer of packets from the FPGA chip to a computer memory via a PCI-Express bus. For faster packet processing, in software system DPDK is used for data transfer control. This paper contains a short introduction to technologies used in the project and the summary of the resulting module design. Performace testing has shown that the module can achieve the target throughput of 200 Gb/s, but also revealed possible ways for further improvements.

![]()
![]()
Jiri Matyas, Milan Ceska, Vojtech Mrazek
Approximate computing, approximate arithmetic circuits, Cartesian genetic programming, SAT based fitness function evaluation, relaxed equivalence checking
Nekonvenční výpočetní techniky
We present a novel method allowing one to approximate complex arithmetic circuits with formal guarantees on the approximation error. The method integrates in a unique way formal techniques employed for approximate equivalence checking into a search-based circuit optimisation algorithm (Cartesian Genetic Programming). The key idea of our approach is to employ a novel search strategy that drives the search towards promptly verifiable approximate circuits. The method was implemented within the ABC tool and evaluated on functional approximation of multipliers (with up to 32-bit operands) and adders (with up to 128-bit operands). Within a few hours, we constructed a high-quality Pareto set of 32-bit multipliers providing trade-offs between the circuit error and size. This is for the first time when such complex approximate circuits with formal error bounds have been presented, which demonstrates an outstanding performance and scalability of our approach compared with the existing methods that have either been applied to synthesis of 8-bit multipliers or a statistical testing has been used only. Our approach thus significantly improves capabilities of existing methods and paves a~way towards an automated design process of provably-correct circuit approximations.

![]()
![]()
![]()
Tomáš Štrba
mobile application, iOS, drum beats recognition, discrete wavelet transform, audio analysis, drum training, GrooveSpired
Zpracování zvuku Uživatelská rozhraní
The main goal is implementation of mobile application for drums training. The application must be capable to analyze and evaluate drumming skills of a drummer using drum beats recognition of recorded audio. Other features of the application are displaying drum notation of different grooves from various music styles and playing audio examples of those grooves. For time-frequency analysis discrete wavelet transform is used in this paper. Results show a true positive rate above 96\% with reasonable time tolerance in the onset detection.
![]()
![]()
Ladislav Mošner
Speaker recognition, Microphone arrays, Beamforming, Room impulse response
Zpracování zvuku
This paper addresses the problem of remote speaker recognition (SRE). Nowadays, systems working with signals from close-talking microphones yield very good results. However, in the case of remotely obtained data, their accuracy decreases considerably. Therefore, we explore the applicability of microphone arrays for recovery from errors of SRE system introduced by the room reverberation, where microphone arrays are purposely positioned set of microphones. We discuss two approaches which are both based on microphone arrays -- beamforming (delay-and-sum) for enhancement of the input signals and the retraining of the SRE system components with the beamformed data. By the combination of both techniques, we have achieved significant improvement of accuracy in comparison with the results obtained with the single-microphone recordings.

![]()
![]()
Kateřina Žmolíková
Speech recognition, Microphone arrays, Beamforming, Dereverberation
Zpracování zvuku VÝZKUM / RESEARCH - výzkumná práce
The paper deals with the problem of speech recognition using distant microphones. The usage of distant microphones is often more convenient in real applications than using the close talking microphone. However, this introduces the problem of noise and reverberation which degrades the accuracy of the speech recognition system. This problem can be reduced by using microphone arrays rather than single microphone. This paper explores the methods of processing of multichannel recordings to enhance the speech, thereby improving the speech recognition performance. To process the array and achieve noise reduction, two different methods (Delay-and-sum and Minimum variance distortionless response beamforming) are explored. For dereverberation, Weighted prediction error method is used. The methods are tested on three different noise robust datasets (AMI, CHiME3 and REVERB). The results achieved on these tasks are comparable with the published results. In this paper, we present the applied methods, analyze the results and discuss the modifications necessary for achieving the results.

![]()
![]()
Kamil Jeřábek
OMNeT++, RINA Architecture, Distributed Application, RINA Simulator
Počítačové sítě VÝZKUM / RESEARCH - výzkumná práce
This paper is focused on application approach in RINA Architecture, on its design and implementation in RINA Simulator in OMNeT++. The work is carried out within research project PRISTINE within which the RINA Simulator is developed. Contribution of this work is to extend the functionality of the simulator by a programming interface and structure for creating distributed applications. There is also presented simple design of Application Programming Interface.

![]()
![]()
Matej Marecek
Domain-Specific Languages, Templates, Configuration Verification, Xtext, Parsers, Interpreters, WinCC OA, SCADA, JavaScript, JVM, CERN
Programovací jazyky a překladače INOVACE / INNOVATION - vylepšení existující metody nebo její implementace, včetně odstranění omezení
CERN (European Organization for Nuclear Research) is one of the biggest research organizations in the world. It heavily uses SCADA (Supervisory Control And Data Acquisition) software for their scientific and industrial machines. This paper tackles a problem of verifying that configuration files used by CERN's SCADA (WinCC Open Architecture) software are correct and comply with CERN standards. The aim was to develop a tool that gives SCADA developers and administrators ability to easily create templates that describe how certain configuration files should look like and determine whether templates match configuration files. This paper introduces a tool that solves the problem by using a specially designed domain-specific programming language and an interpreter of the language. The language itself is based on declarative paradigm and its fundamental capabilities can be extended by JavaScript injection. As for the interpreter, it uses Xtext-based parser to convert configuration files and templates into form of abstract syntax trees (ASTs). The execution itself is a combination of AST interpretation, translation of certain parts of AST into a JavaScript code and running JavaScript code on top of the Java Virtual Machine.

![]()
![]()
![]()
Marek Žák
Hexapod, Legged chassis, Walking robot, Hexapod gaits
Robotika a umělá inteligence
This paper aims on design, construction and control of hexapod robot, which is six-leg walking robot. Basic characteristics of legged robots, a few existing robots and their pros and cons are described. Paper also describes basic gaits, which are used by legged robots for their locomotion. Result of this project is a legged robot, which can walk using tripod, wave and ripple gait and is equipped with sonars, force-sensitive resistors and encoders. Robot is controlled and monitored from user interface program. It can display data from sensors and positions of robot’s legs. The robot can be used to test and verify algorithms, gaits and features of walking robots.

![]()
![]()
Martin Hruška
Forest Automata, Formal Verification, Static Analysis, Complex Data Structures, Tree Automata, Backward Run, Predicate Abstraction
Testování, analýza a verifikace
Forest automata are one of the formalisms recently used for analysis and verification of programs manipulating dynamic data structures. In the area of shape analysis there exists a tool Forester employing forest automata. Forest automata are based on tree automata and Forester has its own implementation of tree automata. However, there is the VATA library which implements the efficient algorithms for the tree automata manipulation, especially the efficient algorithms for the checking inclusion of languages of tree automata what is an operation crucial also for the verification procedure based on forest automata. The first goal of this work is to implement a version of Forester tool that uses the VATA library for tree automata manipulation. The second goal of this work is to extend forest automata based verification with backward run that checks whether a found error is a spurious or a real one what could be used for refinement of predicate abstraction. The first goal has been already fulfilled and the variant of Forester using the VATA library successfully participated in the competition SV-COMP 2015. The part of the second goal is done only partially -- the backward run is already finished and predicate abstraction implementation is in progress.