
![]()
![]()
![]()
Son Hai Nguyen
Augmented Reality, Computer Vision, Image Processing
Zpracování dat (obraz, zvuk, text apod.)
Augmented reality visualizes additional information in real-world environment. Main goal is achieving natural looking of the inserted 2D graphics in a scene captured by a stationary camera with possibility of real time processing. Although several methods tackled foreground segmentation problem, many of them are not robust enough on diverse datasets. Modified background subtraction algorithm ViBe yields best visual results, but because of the nature of binary mask, edges of the segmented objects are coarse. In order to smooth edges, Global Sampling Matting is performed, this refinement greatly increased the perceptual quality of segmentation. Considering that the shadows are not classified by ViBe, artifacts were occurring after insertion of segmented objects on top of the graphics. This was solved by the proposed shadow segmentation, which was achieved by comparing the differences between brightness and gradients of the background model and the current frame. To remove plastic look of the inserted graphics, texture propagation has been proposed, that considers the local and mean brightness of the background. Segmentation algorithms and image matting algorithms are tested on various datasets. Resulted pipeline is demonstrated on a dataset of videos.

![]()
![]()
Michal Hornický
Automated Trading, Bitcoin, Rust, Distributed system
Informační systémy Webové technologie
The success of cryptocurrencies like Bitcoin has created many new opportunities. One of them came somewhere around the year 2012-2013, in a form of an online cryptocurrency exchange. Since then, many new online exchanges were created. These exchanges provide unprecedented ease of use and access to everyone, contrasting existing financial exchanges. Day-trading on these exchanges is easy, and has a large potential because of the extreme volatility of these new markets. This paper outlines the design and implementation of a distributed system, that would facilitate this task. The goals, which include ease of use for new users, scalability for large number of users, and customization for advanced users, combined with problem domain pose interesting requirements, which influenced the design and implementation

![]()
![]()
Adrián Novák, Lukáš Galbička
OMNeT++, OSPFv3, BGPv4, INET, ANSA, Network Simulation
Modelování a simulace Počítačové sítě
This paper deals with modeling and simulation of OSPFv3 and BGPv4 protocols. OSPFv3 and BGPv4 are widely used routing protocols. In their newest version are treated as modern multi-address family protocols, which means they supports both IPv4 and IPv6 routing. The resulting model may be used to demonstrate routing mechanisms in real networks. They are both implemented in OMNeT++ Discrete Event Simulator as a part of ANSA and INET frameworks. A~contribution of this work is that no working model of OSPFv3 has been yet implemented in any other simulators that are similar to OMNeT++. BGPv4 is implemented in INET4 for IPv4 network layer protocol support only and there are some issues with the current version. The version of BGPv4 does not support multi address-family routing.

![]()
![]()
Martin Kruták
Object gauging, Sub-pixel edge detection, Industrial image processing
Zpracování dat (obraz, zvuk, text apod.)
In this paper, a method for dimensional gauging of pellets based on image processing with sub-pixel precision is introduced. The method is intended as a component of a quality control system for pellets. Object gauging from the image is on rise in demand in modern manufacturing processes. Very often, depending on the resulting precision, this is done physically in direct contact with the object itself. In case of soft objects that could be damaged in the process of gauging by standard methods (physical contact gauges) a non-contact method is needed. The method proposed in this paper uses means of sub-pixel edge detection in image combined with the interpolation-based edge methods. Resulting algorithm is fast with industry sufficient accuracy. Experimental results described in the paper show gauging accuracy of 25 micrometers for the side view and accuracy of 10 micrometers for the frontal view.

![]()
![]()
Tomáš Kocman
Kyberkriminalita, Archivace webu, Dolování dat
Bezpečnost Databáze a data-mining
Archivace dat z webu je užitečná pro ty případy, ve kterých si chceme udržovat měnící se informace o nějakém subjektu v čase. Tato práce umožňuje automatizovat archivaci webových stránek, ovšem jen těch, které splňují určitá pravidla – data na nich obsažená vyhovují definovaným regulárním výrazům. Výsledkem práce je platforma, kterou lze konfigurovat takovým způsobem, aby prohledávala a archivovala webové stránky podle různých strategií. Mějme například instituci jako muzeum nebo knihovnu, která by chtěla ukládat historii určitých dokumentů na webu. S platformou lze jednoduše automatizovaně navštívit všechny stránky na daném webu a pokud tyto stránky splňují definovaná pravidla, platforma provede jejich zálohu. V oblasti kyberkriminality například vyšetřovatelé znají webové stránky, popřípadě fórum, kde pachatel prováděl trestnou činnost. Potom můžou platformu využít k nalezení důkazního materiálu – internetovou přezdívku pachatele, obsah zpráv a další pro soud cenné informace.

![]()
![]()
Adam Kövári
yatta, dynamic, functional, programming language, graalvm, truffle framework
Překladače a gramatiky
GraalVM is a relatively new runtime/virtual machine capable of transforming Abstract Syntax Tree (AST) interpreters into highly optimized compilers. GraalVM provides Java API for implementing AST interpreters that dynamically self-rewrite themselves to provide high runtime performance, called Truffle framework. I have designed Yatta language as an experimental language/interpreter built for GraalVM and implemented it using Truffle framework. Actual implementation of Yatta interpreter is currently in progress and most features demonstrated in this paper are implemented or in the state of proof-of-concept implementation and those which are not yet implemented, are clearly marked so. Additionally, there is a clear path towards first release sketched in the Conclusions section. Yatta explores viability of an advanced functional programming language in the GraalVM environment. It delivers advanced features, such as advanced pattern matching, powerful built-in types and data structures, and built-in concurrency. Asynchronous computations are transparent to the programmer and are implemented by the runtime system. While Yatta is currently an area of active research and development, one of the main goal is to retain qualities necessary for real world usage. One of the core principles of this language must be easy readability and powerful standard library, so that the language can succeed against its competitors both in the GraalVM world and among other functional programming languages.

![]()
![]()
Pavel Kohout
P4, Stateful packet processing, FPGA
Počítačová architektura a vestavěné systémy Počítačové sítě
Research and development in area of network technologies allow to increase speed of network traffic up to 100 Gbps meanwhile requirements for its security and an easy administration stay the same. A process of collecting network traffic statistics is important part in the defense of a network infrastructures but its performing is difficult in a high-speed network environment. Nowadays, a P4 language becomes powerful tool for the network administrators thanks to the platform independence and its ability to describe whole packet processing pipeline. The aim of this work is to extend existing stateless solution developed at CESNET association target to FPGA platform by support of stateful processing at speed 100 Gbps. This paper describes the designed system architecture for stateful processing realization in P4 described device respecting requirements for its resources or rate. Performance testing has shown that device is capable of achieving the target throughput of 100 Gbps for limited number of used stateful memory requests in context of a table or an user action.

![]()
![]()
Martin Timko
Ochrana súkromia a bezpečnosť užívateľov internetu, JavaScript Restrictor, JavaScript Zero, rozšírenie webového prehliadača, JavaScript, WebExtensions
Bezpečnost Webové technologie
Cieľom tejto práce je rozšíriť a funkčne vylepšiť prototyp webového rozšírenia vytvoreného Ing. Zbyňkom Červinkom, zamerané na ochranu súkromia užívateľa pri prehliadaní webu. V riešení boli využité nadobudnuté poznatky o fungovaní existujúcich nástrojov pre bezpečnosť a ochranu súkromia, ako napríklad technológia JavaScript Zero. Vytvorené riešenie pomocou techniky zapuzdrenia vhodných JavaScriptových objektov a funkcií, poskytuje užívateľom väčšiu anonymitu pri prehliadaní webu. Rozšírenie JavaScript Restrictor bolo zverejnené a testované používateľmi. Hlavným prínosom práce je zvýšenie ochrany súkromia užívateľa ako aj zvýšenie bezpečnosti pred útokmi spojenými so zberom dát o užívateľoch.
![]()
![]()
David Piškula
Internet of Things, Edge Computing, Autonomous Automation
Počítačové sítě Zpracování dat (obraz, zvuk, text apod.)
The aim of this work is to research the current state of automated Internet of Things networks, describe the problems of existing solutions and design a system that solves some of them. Two of the most common issues are the overdependence on Cloud servers and loss of functionality without an internet connection. The designed system solves these by moving automation from the Cloud to a gateway at the edge of the network. The gateway connects to the Cloud to report device states, store telemetry and receive remote commands, however, it is able to perform automation and data processing even when offline. The result is part of a complete Internet of Things solution used in a smart home model created in cooperation with NXP Semiconductors.
![]()
![]()
![]()
Tomáš Chocholatý
Detekce dopravních značek, Konvoluční neuronové sítě, Dektekce objektů v obraze
Zpracování dat (obraz, zvuk, text apod.)
Článek se zabývá detekcí dopravních značek v~obraze. Cílem této práce je vytvoření vhodného detektoru pro detekci a rozpoznání dopravního značení v~reálném provozu. Problematika detekce je řešena pomocí konvolučních neuronových sítí (CNN). Za účelem trénování neuronových sítí byly vytvořeny vhodné datové sady, které se skládají ze syntetického i reálného datasetu. Pro zhodnocení kvality detekce byl vytvořen program kvantitativního vyhodnocování.

![]()
![]()
![]()
Adam Bezák
rozšírená realita, iOS, mobilná aplikácia, ARKit, SceneKit, OpenStreetMaps
Počítačová grafika
Táto práca si dáva za cieľ zlepšiť užívateľovi orientáciu v teréne pomocou jeho smartphonu a rozšírenej reality. Spojením týchto dvoch prvkov a bezplatnej databáze geografických dát OpenStreetMap je možné zobraziť okolité prvky z máp alebo prípadne zobraziť doplňujúce informácie o okolitých objektoch. Výsledná technológia je použitá v naimplementovanej iOS aplikácii s názvom Water Radar. Táto aplikácia zobrazuje okolité vodné toky (alebo iné vodné objekty) vzhľadom na GPS polohu užívateľa. Aplikácia využíva taktiež Google Elevation API aby zobrazené vodné toky kopírovali reliéf krajiny. V článku je popísaný spôsob získania a spracovania dát vhodných na zobrazenie. Taktiež je vysvetlená technika zisťovania, čo najpresnejšej lokácie užívateľa vďaka ktorej sa odfiltrujú nepresné GPS polohy. Dôraz implementácie je kladený najmä na jednoduché a zrozumiteľné užívateľské rozhranie, kde sa musia napríklad vzdialené prvky zväčšiť alebo odfiltrovať.

![]()
![]()
Pavel Eis
bezpečnostní incident, reprezentace bezpečnostních incidentů, konverze bezpečnostních formátů, platformní konektory
Bezpečnost
Existuje celá řada platforem a systémů určených ke sdílení kybernetických bezpečnostních incidentů a událostí, které často používají rozdílné bezpečnostní formáty. Tímto způsobem dochází ke ztížení nebo přímo nemožnosti sdílení bezpečnostních incidentů a událostí mezi organizacemi, které využívají rozdílné platformy. Řešením tohoto problému může být vznik konvertorů, které jsou schopné převádět používané bezpečnostní formáty mezi sebou. Tato práce se zabývá převodem mezi bezpečnostními formáty IDEA, MISP a STIX. Při konverzi je důležité dbát na postup, aby nedošlo ke ztrátě informací, nebo aby při chybném převodu nevznikl jiný druh události, než byl reprezentován původní událostí. Pokud je převod dostatečně přesný, může být jednodušeji dosaženo přesnější a širší analýzy kybernetických bezpečnostních incidentů.

![]()
![]()
Ondřej Valeš
finite automata, tree automata, language equivalence, language inclusion, bisimulation, antichains, bisimulation up-to congruence
Testování, analýza a verifikace
Tree automata and their languages find use in the field of formal verification and theorem proving but for many practical applications performance of existing algorithms for tree automata manipulation is unsatisfactory. In this work a novel algorithm for testing language equivalence and inclusion on tree automata is proposed and implemented as a module of the VATA library with a goal of creating algorithm that is comparatively faster than existing methods on at least a portion of real-world examples. First, existing approaches to equivalence and inclusion testing on both word and tree automata are examined. These existing approaches are then modified to create the bisimulation up-to congruence algorithm for tree automata. Efficiency of this new approach is compared with existing tree automata language equivalence and inclusion testing methods.
![]()
![]()
Petra Sečkařová
Temporální vlastnosti programů, Monitorování za běhu, Automatická verifikace
Testování, analýza a verifikace
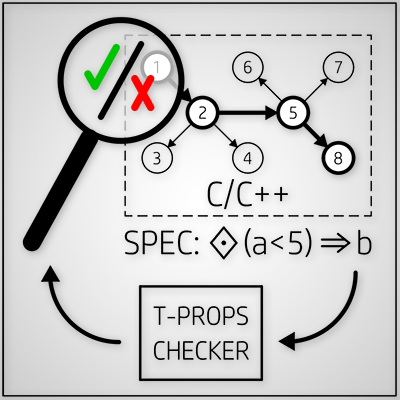
Temporální vlastnosti programů jsou používány ke specifikaci korektního průběhu jejich vykonávání. Jedním z nejčastějších způsobů formálního popisu těchto vlastností je lineární temporální logika - LTL. Tato práce se zabývá návrhem a implementací nástroje pro automatizované ověřování temporálních vlastností běhů programů specifikovaných pomocí tzv. past-time LTL. Výsledný program na základě dané specifikace vygeneruje statickou knihovnu, která dokáže spolehlivě ověřit, zda jsou její formule v každém okamžiku běhu kontrolovaného programu splněny, a případné neočekávané nebo nesprávné chování hlásí společně s podrobnou zprávou o okolnostech tohoto chybového stavu, která má napomáhat k nalezení chyby v konkrétním místě kódu.

![]()
![]()
![]()
Pavel Hřebíček
Mobilní aplikace, Eye Check, Leukokorie, Zdravé oči, iOS, Android, React Native, OpenCV, Dlib, REST
Uživatelská rozhraní Zpracování dat (obraz, zvuk, text apod.)
Cílem této práce je návrh a implementace multiplatformní multijazyčné mobilní aplikace pro rozpoznání leukokorie ze snímku lidského obličeje pro platformy iOS a Android. Leukokorie je bělavý svit zornice, který se při použití blesku může na fotografii objevit. Včasnou detekcí tohoto symptomu lze zachránit zrak člověka. Samotná aplikace umožňuje analyzovat fotografii uživatele a detekovat přítomnost leukokorie. Cílem aplikace je tedy analýza očí člověka, od čehož je také odvozen název mobilní aplikace - Eye Check. K vytvoření multiplatformní aplikace byl použit framework React Native. Pro detekci obličeje a práci s fotografií byly použity knihovny OpenCV a Dlib. Komunikace mezi klientem a serverem je řešena pomocí architektury REST. Výsledkem je mobilní aplikace, která při detekci leukokorie uživatele upozorní, že by měl navštívit svého lékaře.

![]()
![]()
![]()
Tomáš Polášek
Hybrid Ray Tracing, DirectX Ray Tracing, Hardware Accelerated Ray Tracing
Počítačová grafika
The goal of this paper is to assess the usability of hardware accelerated ray tracing in near-future rendering engines. Specifically, the DirectX Ray Tracing API and Nvidia Turing GPU architecture are being examined. The assessment is accomplished by designing and implementing a hybrid rendering engine with support for hardware accelerated ray tracing. This engine is then used in implementing frequently used graphical effects, such as shadows, reflections and Ambient Occlusion. Second part of the evaluation is made in terms of difficulty of integration into a regular game engine - complexity of implementation and performance of the resulting system. There are two main contributions of this thesis, the first one being Hybrid Rendering engine called Quark, which uses hardware accelerated ray tracing to implement above-mentioned graphical effects. The hybrid-rendering approach uses rasterization to perform the bulk of the computation intensive operations, while allowing ray tracing to add additional information to the synthesized image. The second important contribution are the performance measurements of the final system, which include time spent on the ray tracing operations and number of rays cast for different input models. Presented system shows one possible way of using the Nvidia Turing Ray Tracing cores in generating more realistic images. Preliminary measurements of the rendering system show great potential of this new technology, with results of 5 to 12 GigaRays per second on RTX 2080 Ti. The largest problem so far is the integration of this technology into rasterization-based engines. Data needs to be prepared for ray tracing and manually accessed from ray tracing shaders. The second problem is the build-time of acceleration structures, which is in order of milliseconds, even for smaller models with around 50 thousand triangles.

![]()
![]()
Michal Vlnas
spherical harmonics, importance sampling, probability density function, pseudo-random number generators
Modelování a simulace Počítačová grafika Zpracování dat (obraz, zvuk, text apod.)
This paper discusses a novel approach for 3D importance sampling probability density functions represented as spherical harmonics (SH). The proposed method pre-samples all spherical harmonic basis functions using a pseudo-random number generator (PRNG) with known seed and decides which samples will be used for further sampling and records these samples. Any function then can be reconstructed given a vector of SH coefficients and PRNG. This approach has immediate usability in rendering, e.\,g. global illumination, radiance transfer, etc. In the contrary to existing methods, our approach does not require evaluation of any function integrals. The proposed approach generates over 3 million sample per seconds (while using single core) and does not decrease performance with increased size of SH basis.
![]()
![]()
Tomáš Dvořák
překladač, gramatika, syntaktická analýza, generátory syntaktických analyzátorů
Překladače a gramatiky
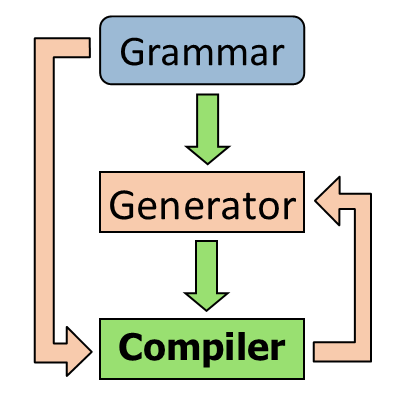
Hlavním cílem tohoto článku je představit architekturu syntaktického analyzátoru a metody jeho algoritmického generování formou nového typu překladače. Důležitým rozšířením tohoto analyzátoru je schopnost analyzovat a přijímat řetězce nepatřící do třídy bezkontextových jazyků, k čemuž byl využit hluboký zásobníkový automat. U metod algoritmického generování analyzátoru je kladen důraz na jazykovou nezávislost výstupu, čímž se výsledná architektura vyznačuje. Protože mezi vstupní gramatiky analyzátoru mohou patřit i některé gramatiky patřící mimo třídu bezkontextových gramatik, byl pro popis vstupních gramatik vytvořen speciální definiční metajazyk, který je v článku, včetně dvou příkladů, důkladně popsán. Výsledkem je prototyp překladače v jazyce Java, který realizuje překlad z definičního metajazyka gramatiky do kódu syntaktického analyzátoru, který přijímá řetězce jazyků generovaných touto gramatikou. Protože se jedná o zcela nový typ analyzátoru, je jeho funkcionalita limitována skutečně implementovanou částí rozhraní na jazyk Java. Navržený analyzátor je vhodný na větší projekty, protože umožňuje hierarchickou delegaci zodpovědnosti za zpracování jednotlivých vstupních syntaktických struktur na více tříd za využití principů dědičnosti. Samotné generování výstupního kódu je realizováno strategiemi, které se odvozují ze vstupní gramatiky.

![]()
![]()
David Pořízek
Transparent encryption, Minifilter driver, Kernel mode
Bezpečnost
The goal of my work is to implement a solution which would be able to extend a Data Loss Protection (DLP) system by preemptively protecting any data which are about to leave an Endpoint. This paper aims to describe the approach that has been used in order to achieve this type of data protection. I have chosen to implement the application using a Windows Minifilter Driver Framework, which provides developers with an interface to directly filter, modify, and create requests sent to file systems (FSs). This approach also inherently provides better security than user mode (UM) solutions, since the framework runs fully in kernel mode (KM) and utilizes security elements that are already in place to protect the Windows Kernel. The application is finished and has been already briefly tested with Safetica DLP. It is able to seamlessly protect user-specified files and provide the user with a plain-text view of said files despite them being stored in an encrypted form on the disk. There are certain limitations to this approach, which will be described in later section but the solution attempts to overcome them in the best possible way. On top of extending DLP systems' functionalities, this work should provide an insight into transparent encryption and more generally, explore the possibilities of a kernel driver when it comes to modification of file views. To a reader, it should present a general idea of what an implementation of this solution entices, a clear starting point for his/her own work, and suggestions how to further improve it.

![]()
![]()
David Průdek
Detekce osob, IoT, Bluetooth, PIR, Home-Assistant, Domácí automatizace, ESP32, Vestavěný systém
Počítačová architektura a vestavěné systémy
Cílem této práce je navrhnout a implementovat senzor detekce přítomnosti osob v místnosti vhodný pro použití v domácí automatizaci. Zaměřil jsem se na nalezení takového řešení, které pro svou činnost využívá běžné nositelné elektroniky. Senzor umístěný v místnosti detekuje tato nositelná zařízení a na základě síly signálu určí jeho pozici. Pro tento případ užití jsem použil technologii Bluetooth LE, která bývá součástí většiny nositelné elektroniky a v poslední době se často využívá k navigaci ve vnitřních prostorech. Použití tohoto senzoru pro automatizaci je zajištěno pomocí systému Home-Assistant. Hlavním přínosem této práce je levně a jednoduše rozšířit možnosti běžné domácí automatizace detekci osob v jednotlivých místnostech, nikoli pouze v široké oblasti, kterou nabízejí lokace pomocí GPS nebo připojení k Wi-Fi přístupového bodu.

![]()
![]()
Drahomír Dlabaja
Light field, Lossy compression, JPEG, Transform coding, Plenoptic representation, Quality assessment
Zpracování dat (obraz, zvuk, text apod.)
This paper proposes a light field image encoding solution based on four-dimensional discrete cosine transform and quantization. The solution is an extension to JPEG baseline compression. A light field image is interpreted and encoded as a four-dimensional volume to exploit both intra and inter view correlation. Solutions to 4D quantization and block traversal are introduced in this paper. The experiments compare the performance of the proposed solution against the compression of individual image views with JPEG and HEVC intra in terms of PSNR. Obtained results show that the proposed solution outperforms the reference encoders for light images with a low average disparity between views, therefore is suitable for images taken by lenslet based light field camera and images synthetically generated.
![]()
![]()
Matúš Bako
Počítačové videnie, Neurónové siete, Rekonštrukcia obrazu
Robotika a umělá inteligence
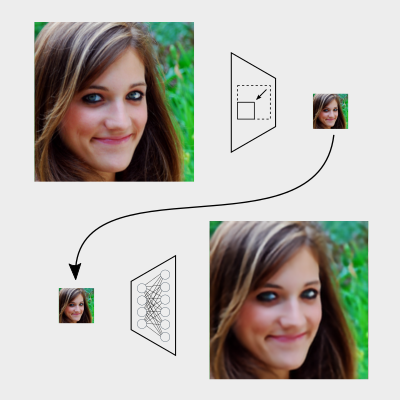
Pri práci s obrázkami tváre sa môžeme dostať do situácie, kedy rozlíšenie bude jednoducho nepostačujúce a algoritmické metódy na zväčšovanie obrázkov nepresné. V takomto prípade sa ponúka možnosť použiť konvolučnú neurónovú sieť, ktorá sa snaží zväčšiť vstupný obrázok a odstrániť prípadné defekty ako šum a rozmazanie. Experimenty ukázali, že mnou navrhnutá architektúra sa na dátovej sade FFHQ dokáže vyrovnať existujúcim architektúram konvolučných neurónových sietí kvalitou, a taktiež zachovaním identity. Takto natrénované modely je možné použiť v praxi na miestach, kde je zväčšovanie tvári potrebné, napríklad pre rozpoznanie identity.

![]()
![]()
David Bažout, Daniel Kolínek
Automatizace, Sběr dat, Vizualizace, Informační systém
Databáze a data-mining Informační systémy Počítačová architektura a vestavěné systémy Uživatelská rozhraní Webové technologie
Cílem tohoto článku je představit začínající start-up FactoryMonitor. Naším produktem je monitorovací a řídící systém vytvořený na míru potřeb zákazníka. Nesnažíme se o převratné inovativní řešení, využíváme stávající technologie, snažíme se s nimi nakládat efektivně a poskytnout zákazníkovi cenově dostupné a minimalistické řešení. Systém umožňuje sbírat hodnoty ze širokého spektra senzorů umístěných i ve fyzicky vzdálených lokalitách, ukládání historických hodnot, přehlednou vizualizaci na míru konkrétnímu zákazníkovi, automatizované i manuální ovládání vzdálených výstupů a přístup k chytrým statistikám. Součástí projektu je průzkum možností a návrh architektury hardwarové i softwarové realizace celého systému. Načerpané teoretické znalosti se nám podařilo proměnit v reálné a fungující řešení monitorovacího systému. Vedením konstruktivní diskuze se zákazníky získáváme stále spoustu nových informací a hledáme nové cesty ke zlepšení výsledného produktu.
![]()
![]()
![]()
Jan Pawlus
signature forgery, handwriting characteristics, dynamic biometric attributes
Bezpečnost Počítačová architektura a vestavěné systémy
This project deals with designing and assembling a device for imitation of static and dynamic handwriting characteristics. First part describes design of a system, which is composed of a special pen targeted for getting static and dynamic characteristics of handwriting, working with these characteristics and an imitation with a 3D printer altered for this purpose. The key of this system is data obtained from user's handwriting with help of specific sensors - this data is used for reconstruction of the pen's trajectory during the writing as well as for analyzing the dynamic biometric attributes of the writer, followed by conversion to G-Code, executed by a 3D printer. This topic might be interesting because research about this specific topic, which would include a real demonstration of how a signature can be forged using dynamic handwriting characteristics, barely exists. The problem with preventing forgery is that we need to know the attack well - this is the point of this project and it is also why Brno's criminal police are interested in this topic.

![]()
![]()
Martin Urbanczyk
Football, simulator, machine learning, match prediction
Informační systémy Robotika a umělá inteligence Uživatelská rozhraní Webové technologie
The goal of this project is to create a web football simulator, which would simulate realistic matches of the football world. The concept of the whole simulator is complex. It generates future results based on real historical match results. However, unpredictable and crazy results are also a part of the fun. Each user has its own simulation and he or she can have completely different results, which are more and more diverse year after year of the simulation. Because of the complexity of football world, the simulator supports only selected football nations. The main focus of the project is to improve the simulation of matches. Calculation of match results is based on real historical results and it uses neural networks. It is mixed with random factors described in the paper. The project focuses on the group of football fans who would like to only watch simulations of the football world without the need to manage teams and players. This is something that is not available on the current market. Every game focuses on management mainly, not the simulation. The core of the simulator could be also used for trying to predict real football matches because it is based on the real data. This paper describes base concepts of predicting a football match. It presents football systems and shows, how the simulator game is different from existing solutions.
![]()
![]()
Eva Navrátilová
Software Engineering, User Interface, Genealogy, C++, Qt
Uživatelská rozhraní
This paper describes the design and implementation of an application for interactive family-tree making. The design of the application stands on two pillars. The first of them being the utilization of design patterns (for example decorator or factory), the second of them being modularity. These design decisions were made in order to simplify eventual revision or expansion of the application in the future.The main aim of the application is to provide a~multi platform tool for managing genealogical data. The data can be imported and exported in GEDCOM format. The program provides an interface for editing and connecting the data about people, families and sources of information. This data can be visualized in exportable family trees and reviewed via pedigree statistics.

![]()
![]()
David Hél
Tax, Form, Web application
Uživatelská rozhraní
The goal of this project is to develop interactive forms for tax returns which are pretty easy to fill in for everyone without any experience in economy or the tax law. The main purpose is to create simple forms for different types of people (e. g., businessman, employee, or student). The official application for tax returns (EPO) provided by The Ministry of Finance of the Czech Republic is complex. It offers many options which are usually unimportant for common users. hence, it is often difficult to achieve the right result. This paper presents a new web application called “Přiznání” which solves the problem by providing a set of simple yes/no questions to the users. The questions are based on the experience of revenue officers and taxpayers who need to fill the forms every year. After the answering all these questions, the user can download a correctly filled form which can be send off to the revenue authority. At the current stage, the application provides the form for businessmen. It successfully generates the Personal Income Tax form—the official document containing the information about personal income tax. The forms for different types of people are being developed.

![]()
![]()
Michal Koutenský
network architecture, RINA, rlite
Počítačové sítě
The purpose of this paper is twofold — first, to showcase my contributions to the rlite networking stack, and second, to inform readers about the existence of Recursive InterNetwork Architecture (RINA) and to serve as a quick and easy to read introduction to the architecture and its capabilities. It is well documented that the TCP/IP network architecture suffers from numerous deficiencies and does not meet the demands of modern computing. A great number of these issues are structural and cannot be properly solved by making adjustments to existing protocols or introducing new protocols into the stack. RINA is a clean slate architecture whose aim is to be a more general, robust and dynamic basis for building computer networks. I have extended the rlite implementation with support for policies. With this framework in place, it is possible to have multiple behaviours of components (such as routing), and change between these during runtime. This additional flexibility and simple extensibility greatly benefits both production deployment scenarios as well as research efforts. As policies are crucial for RINA, supporting them is an important milestone for the implementation, and will hopefully foster adoption and accelerate development of RINA as a viable replacement for current Internet.

![]()
![]()
David Bažout
detekce tváře, rozpoznávání tváře, dohledový systém
Zpracování dat (obraz, zvuk, text apod.)
Cílem této práce je vytvořit nástroj umožňující vyhledávání podezřelých osob ve videozáznamu pocházejícího z dohledových kamer. Hledané osoby jsou systému určeny pomocí několika fotografií obličeje. Výstup tvoří informace o výskytu hledaných osob na konkrétních snímcích. Úloha je řešena rozdělením problému na úlohu detekce tváře a její následnou identifikaci. Experimenty s existujícími přístupy na vhodných datových sadách poskytují relevantní porovnání úspěšnosti metod v různých situacích z reálného provozu. Výstupy testů poskytují informace o vhodných metodách a jejich optimálním nastavení pro tuto konkrétní úlohu. Práce se zabývá i návrhem vhodné architektury, průzkumem existujících knihoven implementujících zkoumané metody a dalšími způsoby optimalizace výpočtu. Výsledkem je implementace modulu, který splňuje zadané parametry.

![]()
![]()
Vojtěch Večeřa
password recovery, hashcat, GPU, benchmarks, HW acceleration, OpenCL
Bezpečnost Počítačová architektura a vestavěné systémy Počítačové sítě
This paper discusses the Graphics Processing Unit (GPU) model selection for GPU accelerated computation nodes with focus on password recovery. The compared GPU models fit the gaming mid and high-end categories. Other configuration components are stable and consist of the commonly available hardware. The paper presents a designed benchmark and stability test set as well as their processed and aggregated results. The set focuses not only on mask and dictionary attack recovery speeds, but also on power consumption, and cooling sufficiency. The paper finishes with the financial aspects of purchasing and keeping the node working over an expected GPU lifetime period. The results confirm Nvidia GeForce RTX 2080Ti as the most potent out of the tested models as well as performance similarities of Nvidia GeForce GTX 1070Ti with a GTX 1080Ti and Nvidia GeForce GTX 1060 6G and AMD Radeon RX 580 8GB. The Nvidia GeForce GTX 1070Ti is also the universal card when considering performance, power consumption, and purchase prices.
![]()
![]()
Filip Badáň
Evolutionary algorithms, Convolutional neural networks, Neuroevolution
Robotika a umělá inteligence
Designing deep convolutional neural networks, which are nowadays successfully applied in a wide range of various fields, can be a very challenging task requiring a great deal of experience. The aim of this work is to minimize human effort needed to design convolutional neural networks and automatize the whole process of finding efficient and successful architectures. Proposed framework uses a modified version of an evolutionary algorithm, which is developed to find accurate and fully-trained convolutional neural networks to solve various image classification problems. The framework uses the so-called weight inheritance technique, which allows the training process to be considered as a special kind of mutation and by that drastically reduce time complexity of the evolution cycle. An innovative concept of the training age which gives "younger" but potentially better candidates an opportunity to succeed is also proposed. The framework has been validated on the standard image classification data sets -- MNIST and CIFAR10. The initial experiments yielded fully-trained networks with almost 99\% test accuracy on MNIST data set in a relatively short evolution time. The results showed that neuroevolution has a promising potential to automatize the process of designing neural networks.
![]()
![]()
![]()
Filip Kočica
Konvoluční neuronová síť, YOLO, Detekce, Syntetická, Dopravní značka
Zpracování dat (obraz, zvuk, text apod.)
Tato práce řeší problematiku detekce dopravního značení za pomoci moderních technik zpracování obrazu. K řešení byla použita speciální architektura hluboké konvoluční neuronové sítě zvaná YOLO, tedy You Only Look Once, která řeší detekci i klasifikaci objektů v jednom kroce, což celý proces značně urychluje. Práce pojednává také o porovnání úspěšnosti modelů trénovaných na reálných a syntetických datových sadách. Podařilo se dosáhnout úspěšnosti 63.4% mAP při použití modelu trénovaného na reálných datech a úspěšnosti 82.3% mAP při použití modelu trénovaného na datech syntetických. Vyhodnocení jednoho snímku trvá na průměrně výkonném grafickém čipu ~40.4ms a na nadprůměrně výkonném čipu ~3.9ms. Přínosem této práce je skutečnost, že model neuronové sítě trénovaný na syntetických datech může za určitých podmínek dosahovat podobných či lepších výsledků, než model trénovaný na reálných datech. To může usnadnit proces tvorby detektoru o nutnost anotovat velké množství obrázků.
![]()
![]()
Nikola Valešová
Machine learning, Metagenomics, Bacteria classification, Phylogenetic tree, 16S rRNA, DNA sequencing, scikit-learn
Bioinformatika
This work deals with the problem of automated classification and recognition of bacteria after obtaining their DNA by the sequencing process. In the scope of this paper, a~new classification method based on the 16S rRNA gene segment is designed and described. The presented principle is based on the tree structure of taxonomic categories and uses well-known machine learning algorithms to classify bacteria into one of the connected classes at a~given taxonomic level. A~part of this work is also dedicated to implementation of the described algorithm and evaluation of its prediction accuracy. The performance of various classifier types and their settings is examined and the setting with the best accuracy is determined. Accuracy of the implemented algorithm is also compared to an existing method based on BLAST local alignment algorithm available in the QIIME microbiome analysis toolkit.

![]()
![]()
Matej Karas
Vulkan, Clustered shading, Deferred rendering, Graphics, Many lights, Real-time rendering
Počítačová grafika
Táto práca sa zaoberá metódou vykresľovania viacerých svetiel v reálnom čase. Výpočet osvetlenia je drahá operácia a pri naivných technikách (ktoré síce postačujú pre aplikácie s nízkym počtom svetiel), často dochádza k redundantným výpočtom. Cieľom práce je implementovať metódu clustered deferred shading v aplikačnom rozhraní Vulkan a efektívne vykresľovať viacero svetiel v reálnom čase. V terajšej implementácii sa podarilo efektívne zredukovať počet svetelných kalkulácií a tým urýchliť vykresľovanie resp. zvýšiť FPS a to až 100-násobne pri 10k a viac svetlách v~scéne voči klasickému deferred shadingu.
![]()
![]()
Daniel Dušek
Penetration Testing Automation, Web Application Penetration Testing, Web Application Penetration Testing Methodology, Open Source Intelligence Automation, Automated Security Testing
Bezpečnost
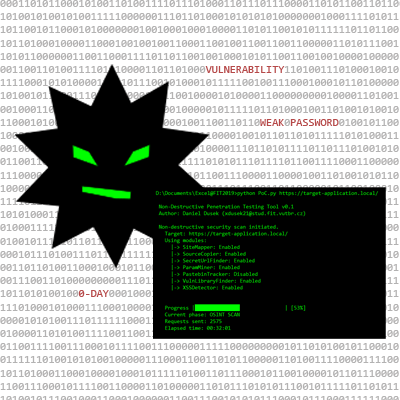
Penetration testing of a company's web application on a regular basis comes either with the fear of possible downtime, or with the need for setting up the test environment. This work aims to offer the solution that will both minimize the fear and remove the need for a separate testing environment and will also enable automated regular security scans. This paper presents a new, generally applicable approach to the web application penetration testing that leans heavily towards the automation while at the same time is non-destructive and leaves no permanent traces of the testing on the target application. The proposed approach can serve as a guiding line for implementation of a tool that automates a portion of the standard penetration testing and eases a tester's work. Applicability of this approach is supported through the proof of concept implementation that follows it. A reader of the paper can adapt the proposed approach to developing their own penetration testing tool.
![]()
![]()
Jakub Pruzinec
malware analysis, static analysis, classification, features, reverse engineering, binary file
Bezpečnost Testování, analýza a verifikace Zpracování dat (obraz, zvuk, text apod.)
Rapid and widespread adoption of information technologies lead to userbase diversification and their use among laymen. Due to this, we witness malicious software evolve and grow larger day by day endangering data of billions of users. Today's anti-malware companies seek automated solutions for malware detection. One of possible approaches to malware identification is to use artificial intelligence to classify it. Precision of malware classification is heavily dependent on available information about classified samples - features. Poor design of features may result in wrongly classifying legitimate software as malware, or even worse, to let malware slip by undetected. This article focuses on design, extraction, reliability and efficiency testing of static binary malware features. Moreover, malware feature extraction tool, FileInfo, is innovated. Work is done in cooperation with Avast company, where FileInfo is used in malware clustering system, binary file decompiler and as a general purpose static analysis tool on a daily basis.

![]()
![]()
Martin Smutný
formal verification, static analysis, 2LS framework, abstract interpretation, invariant, template-based analysis
Testování, analýza a verifikace
The goal of this work is to propose a way to improve precision of program analysis in the 2LS framework, based on its existing concepts, mainly template-based synthesis of invariants. 2LS is program analysis framework for C programs, which relies on the use of an SMT solver for automatic invariant inference. One of the techniques of 2LS’ main algorithm is abstract interpretation, which is used for invariant inference and thanks to its over-approximations, makes the computation of invariants easier. The proposed solution analyses the computed invariants, and identifies the parts of the invariant that cause an undecidability of the verification. Using the obtained information, the designed method is able to identify the variables of the original program, which determine whether a verification is successful. The solution can be used to locate unbounded or imprecise variables inside loops of the original program, that might be the cause of program errors. Also the output of the designed method can be used in further analyses, now focused on further constraining or refining the values of imprecise variables.

![]()
![]()
Martin Minárik, Adam Jurczyk
Augmented Reality, 3D object multi-user interaction, ARKit 2
Počítačová grafika
The aim of this paper is to showcase a possible solution that allows multiple people to interact with a single customizable object in a shared augmented reality session. The work makes use of the new features available in ARKit 2 to share the AR session. It also demonstrates 3D object handling and customization with changes synchronized in real-time to all connected users, as well as resolving conflicts resulting from multiple people interacting with the same single object. Our goal is to demonstrate the possible use and benefits in presenting work from a designer to a client in real environment with immediate interactive input from the client.
![]()
![]()
David Hříbek
Data-Matching, Deduplication, Parish Records, Normalization
Databáze a data-mining
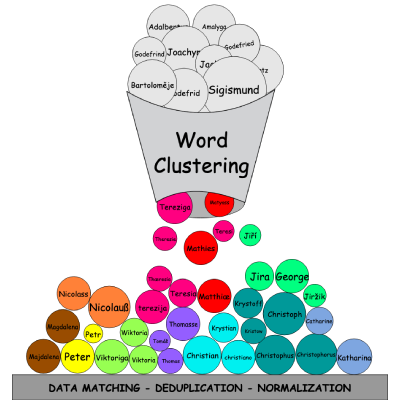
V této práci je řešeno shlukování slov z matričních záznamů tak, aby v každém shluku byla slova, která jsou si navzájem velmi podobná. V řešení bylo použito procesu deduplikace záznamů, který byl pozměněn tak, aby odpovídal požadavkům práce. Díky roztřídění záznamů do shluků bylo následně možné tyto shluky normalizovat, tedy přidělit celým shlukům nebo jednotlivým slovům jejich normalizované názvy. V rámci práce byla přidána možnost normalizace slov do již existující webové aplikace, pro správu matričních záznamů, DEMoS. Díky normalizaci slov jsou matriční záznamy lépe čitelné a je mezi nimi možné snadněji vyhledávat.

![]()
![]()
Jan Jileček
Neurofeedback, ADHD, OpenBCI, Ultracortex, BCI, mind-controlled game, EEG, ADD, biofeedback, neural networks, brain, focus, attention, prefrontal cortex, motor cortex, meditation, corpus callosum, python, unity, lstreamer, gui, openvibe, 10-20 system, brain waves
Bioinformatika Robotika a umělá inteligence
Cílem této práce je implementovat myslí ovládanou hru, která bude sloužit jako alternativní domácí verze klinického neurofeedbacku. Neurofeedback je biofeedback metoda pro léčbu ADHD a dalších kognitivních postižení. Dalším cílem této teze je vytvoření hry ovládané sensorimotorickým kortexem, jinými slovy, představení si pohybu ruky vyprodukuje výstup ve hře, např. herní charakter se pohne doprava. V této práci používám OpenBCI EEG headset a vlastní software pro zachycování a zpracování EEG dat. Jako první krok jsem vyvinul tzv. “Visual Prompter”, který předkládá uživateli výzvy, a slouží tak jako víceúčelový sběrač datových sad. Hra samotná spoléhá na interpretaci dat z headsetu – k tomu používám detekci alfa/beta vln a v další fázi používá neuronové sítě pro klasifikaci dat. Obojí probíhá v reálném čase a je tak zajištěno ovládání hry. Porovnám zde více existujících výzkumů, jejich metody a úspěšnost.
![]()
![]()
Ján Profant
speaker verification, neural networks, deep learning
Zpracování dat (obraz, zvuk, text apod.)
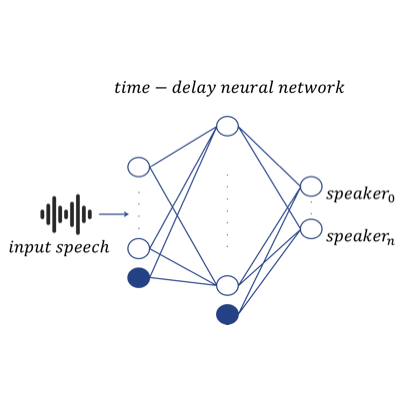
The objective of this work is to study state-of-the-art deep neural networks based speaker verification systems called x-vectors on wideband conditions, such as YouTube. This system takes variable length audio recording and maps it into fixed length embedding which is afterward used to represent the speaker. We compared our systems to BUT's submission to Speakers in the Wild Speaker Recognition Challenge (SITW). We observed, that when comparing single best systems, with recently published x-vectors we were able to obtain more than 4.38 times lower Equal Error Rate on SITW core-core condition compared to SITW submission from BUT. Moreover, we find that diarization substantially reduces error rate when there are multiple speakers for SITW core-multi condition but we could not see the same trend on NIST Speaker Recognition Evaluation 2018 Video Annotations for YouTube data.

![]()
![]()
Radek Pazderka
Segmentace obrazu, konvoluční neuronová síť, analýza dopravy, DeepLabv3+
Zpracování dat (obraz, zvuk, text apod.)
Tento článek se věnuje problému segmentace scény z dopravního prostředí řešený pomocí hlubokých neuronových sítí. Popisuje celý proces vývoje. Konkrétně se jedná o přípravu datové sady a její rozšíření o nová vygenerovaná data pomocí GTAV. Následně je uveden model sítě DeepLavV3+ a jeho proces trénování. V závěru se tento natrénovaný model optimalizuje pomocí TensorRT na GPU a následně testuje jeho kvalita.

![]()
![]()
Michaela Bieliková
bioinformatics, metagenomics, bacterial functional profile, KO profile, 16S rRNA
Bioinformatika
Humans are hosts to an enormous variety of microbes, bacterial, archaeal, fungal, and viral. Unfortunately, science knows only little about them. Since most of the bacteria has not been studied yet, the main question for a given sample is not only which species of bacteria a specific sample contains, but also what can the bacteria in this sample do (i.e. lipid digestion or resistance to antibiotics). This task is called functional profile prediction and it will be the main focus of this paper. In this paper, I introduce methods for functional analysis, describe existing tools and then design a new tool inspired by them, which implements different methods for the prediction. The results of the experiments imply, that the implemented tool is accurate and useful when using the classic method for experimental evaluation. However, I propose a new approach to evaluation, that concerns only the most specific bacterial functions, where the results differ from the classic one. In the end, I discuss possible implications of this difference.

![]()
![]()
Jan Kohút
rozpoznávání textu, rekurentní neuronové sítě, konvoluční neuronové sítě, adaptace, aktivní učení, dataset IMPACT
Robotika a umělá inteligence Zpracování dat (obraz, zvuk, text apod.)
Cílem této práce je srovnání architektur neuronových sítí pro rozpoznávání textu. Dále pak adaptace neuronových sítí na jiné texty, než na kterých byly učeny. Pro tyto experimenty využívám rozsáhlý a rozmanitý dataset IMPACT o více než jednom milionu řádků. Pomocí neuronových sítí provádím kontrolu vhodnosti řádků tzn. čitelnost a správnost výřezů řádků. Celkem srovnávám 6 čistě konvolučních sítí a 9 rekurentních sítí. Adaptace provádím na polských historických textech s~tím, že trénovací data adaptovaných sítí neobsahovaly texty ve slovanských jazycích. Adaptace využívají přístupy aktivního učení pro výběr nových adaptačních dat. Čistě konvoluční sítě dosahují úspěšnosti 98.6 \%, rekurentní sítě pak 99.5 \%. Úspěšnost sítí před adaptací se pohybuje kolem 79\%, po postupné adaptaci na 2500 řádcích stoupne úspěšnost na 97 \%. Přístupy aktivního učení dosahují lepší úspěšnosti než náhodný výběr. Pro zpracování datasetů je vhodné používat již natrénované neuronové sítě tak, aby se odstranilo co možná nejvíce chybných dat. Rekurentní vrstvy znatelně zvyšují úspěšnost sítí. Při adaptaci je výhodné využívat přístupů aktivního učení.

![]()
![]()
![]()
Miroslav Karásek
Augmented reality, Measurement, Android, ARCore, Point Cloud
Počítačová grafika Uživatelská rozhraní
This article describes the technology for automatic measurement of overall dimensions of a generic object using a commercially available mobile phone. The user only has to go around the measured object and scan it by the mobile phone’s camera. The measurement uses computer vision algorithms for scene reconstruction in order to obtain the object’s point cloud. This paper proposes algorithms for processing the point cloud and for estimating the dimensions of the object. It focuses on collecting and filtering points where the biggest challenge is to recognize and separate points belonging to the measured object from the rest. Proposed algorithms were tested on an implemented Android application using ARCore technology. The result of measurement on a cuboid object had the error about 1cm. An object with other shapes achieves measurement error from 3 to 5cm. The measurement error was independent on object size. This implies that the algorithm is more accurate for larger objects with the shape approaching cuboid.

![]()
![]()
Ján Jusko
chatbot, konverzačný agent, užívateľské rozhranie
Uživatelská rozhraní
Táto práca popisuje vývoj chatbota pre štatutárne mesto Brno. Chatbot je moderý komunikačný prostriedok založený na konverzácii človeka s počítačom priridzeným spôsobom prostredníctvom textovej interakcie. Motivaciou je skutočnosť, že spôsob komunikácie samosprávnej časti so svojimi obyvateľmi sa stáva zastaralým. Obyvateľom miest zvyčajne nie je poskytnutý jeden, unifikovaný zdroj informácií a noviniek ale viacero. Práve preto je pre mnohých obyvateľov náročné získavať aktuálne informácie o dianí v samospráve. Tento problém sa snažíme vyriešiť vytvorením konverzačného agenta --- chatbota, s ktorým obyvatelia samosprávy môžu komunikovať prirodzeným jazykom a jednoduchým spôsobom tak dopytovať a prijímať požadované informácie. Výsledkom práce je kompletný návrh aj implementácia chatovacieho robota ktorý zvláda ako obecné, tak aj Brnu-špecifické otázky. Hlavným prínosom tejto práce je priblíženie samosprávy k obyvateľstvu a uľahčenie získavania informácií spôsobom primeraným dnešnej modernej dobe.

![]()
![]()
![]()
Karolína Klepáčková
Packet bypass, Android, Security
Bezpečnost
Global problem with mobile applications whose provide some kind of internet communication is that any of them doesn't provide information about used protocols. Users connecting to public networks are at risk because attackers can eavesdrop on unsecured communications. Knowing the communication protocol and data provided to the application, a knowledgeable user can decide if it's trustworthy or not. This article aims at an Android application which enables security monitoring of other applications' communication which is called AppCheck. Describes the solution of major problems for analyzing network communication of given mobile application. A reader can find out useful information about how to circumvent the Android restrictions on getting information from other applications. Specifically, it focuses on packet processing inside a mobile phone and allocating data flow to individual applications. Thanks to the solution of these problems it can find out how much is the application safe. The implemented application can catch network flow of another application and save it into pcap file which is readable eg. via Wireshark tool. This file is used for making analytics to recognize how much packets were sent in a secure way. All of these features are provided without the necessity of having higher user privileges than the common user has.

![]()
![]()
Šimon Stupinský
Performance, Continuous integration, Non-parametric analysis, Regressogram, Moving average, Kernel regression, Automated changes detection, Difference analysis
Testování, analýza a verifikace
Current tools that manage project performance do not provide a satisfying evaluation of the overall performance history, which is often crucial when developing large applications. In our previous work, we introduced a tool-chain that collected set of performance data extrapolated these data into a performance model represented as a function of two depending variables and compared the result with the model of the previous version reporting possible performance changes. The solution was, however, dependent on precisely specifying and measuring those dependent variables. In this work, we propose a more flexible approach of computing performance models based on collected data and a subsequent check for performance changes that requires only one measured kind of variable. We evaluated our solution on different versions of vim, and we were able to detect a known issue in one of the versions as well as verify that between two stable versions there were no significant performance changes.

![]()
![]()
Matúš Liščinský
Performance bugs, Fuzz testing, Workload mutation, Worst-case, Algorithmic vulnerability, Denial-of-service
Testování, analýza a verifikace
Coding new features is sometimes referred to as "bringing new issues into the program". And to detect these issues, especially performance issues, we often have to reach the point where ordinary inputs can never get. In this work we aim to construct automatic generator of inputs whose task will be to trigger performance fluctuations. Classical solution to automatic generation is so called fuzz testing, which is unfortunately focused on functional bugs only. So we propose to tune its rules and ways of processing the information about program run, to particularly trigger the performance bugs. We integrate our fuzzer into a performance profile manager Perun, which stores data about every run as a profile and can compare profiles of different versions. This way, we can prove that executing with certain file takes more time or memory. We tested our solution on several artificial projects which its potential when the time of program run was extended severalfold. The benefit of such solution would help developers regularly test every version of project for performance bugs and avoid them completely by automatically finding new faulty inputs.

![]()
![]()
Josef Jon
neural machine translation, context, transformer, document level translation
Zpracování dat (obraz, zvuk, text apod.)
This works explores means of utilizing extra-sentential context in neural machine translation (NMT). Traditionally, NMT systems translate one source sentence to one target sentence without any notion of surrounding text. This is clearly insufficient and different from how humans translate text. For many high resource language pairs, NMT systems output is nowadays indistinguishable from human translations under certain (strict) conditions. One of the conditions is that evaluators see the sentences separately. When evaluating whole documents, even the best NMT systems still fall short of human translations. This motivates the research of employing document context in NMT, since there might not be much more space left to improve translations on sentence level, at least for high resource languages and domains. This work sumarizes recent state-of-the art approaches, implements them, evaluates them both in terms of general translation quality and on specific context related phenomena and analyzes their shortcomings. Additionaly, context phenomena test set for English to Czech translation was created to enable further comparison and analysis.

![]()
Martin Vondráček
Network Traffic Analysis, Reverse Engineering, Application Crippling, Penetration Testing, Hacking, Social Applications, Unity, Bigscreen, HTC Vive, Oculus Rift
Bezpečnost Počítačové sítě
Immersive virtual reality is a technology that finds more and more areas of application. It is used not only for entertainment but also for work and social interaction where user's privacy and confidentiality of the information has a high priority. Unfortunately, security measures taken by software vendors are often not sufficient. This paper shows results of extensive security analysis of a popular VR application Bigscreen which has more than 500,000 users. We have utilised techniques of network traffic analysis, penetration testing, reverse engineering, and even application crippling. We have found critical vulnerabilities directly exposing the privacy of the users and allowing the attacker to take full control of a victim's computer. Found security flaws allowed distribution of malware and creation of a botnet using a computer worm. Our team has discovered a novel VR cyber attack Man-in-the-Room. We have also found a security vulnerability in the Unity engine. Our responsible disclosure has helped to mitigate the risks for more than half a million Bigscreen users and all affected Unity applications worldwide.

![]()
![]()
![]()
Šimon Podlesný
MiTM, Ansible, Docker, Raspberry Pi, eaphammer
Bezpečnost
This article is focused on design of MiTM attack with use of modern approaches in IT infrastructure. Especially it's focused on how to simplify configuration of single-board computer for penetration testing purposes by creating scalable infrastructure for device configuration and control. It's also trying to solve problem of disjunction between physical and network security, where professionals for physical security lack technical skills needed for network attacks and vice versa. Proposed solution allows the usage of complicated attacks by trained staff while not limiting users with experience in network security. While today, applications capable of MiTM attacks are monolithic and device-centric, proposed solution considers the device providing MiTM just as one part of the solution and also focuses on other problems like data exfiltration or hash cracking. This was made possible mostly by using Docker, Ansible and Python.

![]()
![]()
![]()
Patrik Goldschmidt
TCP Reset Cookies, TCP SYN Flood, DDoS mitigation
Počítačové sítě
TCP SYN Flood is one of the most widespread DoS attack types used on computer networks nowadays. As a possible countermeasure, this paper proposes a long-forgotten network-based mitigation method TCP Reset Cookies. The method utilizes the TCP three-way-handshake mechanism to establish a security association with a client before forwarding its SYN data. Since the nature of the algorithm requires client validation, all SYN segments from spoofed IP addresses are effectively discarded. From the perspective of a legitimate client, the first connection causes up to 1-second delay, but all consecutive SYN traffic is delayed only by circa 30 microseconds. The document provides a detailed description and analysis of this approach, as well as implementation details with enhanced security tweaks. The project was conducted as a part of security research by CESNET. The discussed implementation is already integrated into a DDoS protection solution deployed in CESNET's backbone network and Czech internet exchange point at NIX.CZ.

![]()
![]()
Daniel Uhříček
IoT, Malware, Linux, Security, Dynamic Analysis, Network Analysis, SystemTap
Bezpečnost
Weak security standards of IoT devices levereged Linux malware in past few years. Exposed telnet and ssh services with default passwords, outdated firmware or system vulnerabilities -- all of those are ways of letting attackers build botnets of thousands of compromised embedded devices. This paper emphasizes the importance of open source community in the field of malware analysis and presents design and implementation of multiplatform sandbox for automated malware analysis on Linux platform. Project LiSa (Linux Sandbox) is a modular system which outputs json data that can be further analyzed either manually or with pattern matching (e.g. with YARA) and serves as a tool to detect and classify Linux malware. LiSa was tested on recent IoT malware samples provided by Avast Software and it solved various problems of existing implementations.
![]()
![]()
Dominik Harmim, Vladimír Marcin, Ondřej Pavela
Facebook Infer, Static Analysis, Abstract Interpretation, Atomicity Violation, Concurrent Programs, Performance, Worst-Case Cost, Deadlock
Testování, analýza a verifikace
Static analysis has nowadays become one of the most popular ways of catching bugs early in the modern software. However, reasonably precise static analyses do still often have problems with scaling to larger codebases. And efficient static analysers, such as Coverity or Code Sonar, are often proprietary and difficult to openly evaluate or extend. Facebook Infer offers a static analysis framework that is open source, extendable, and promoting efficient modular and incremental analysis. In this work, we propose three inter-procedural analysers extending the capabilities of Facebook Infer: Looper (a resource bounds analyser), L2D2 (a low-level deadlock detector), and Atomer (an atomicity violation analyser). We evaluated our analysers on both smaller hand-crafted examples as well as publicly available benchmarks derived from real-life low-level programs and obtained encouraging results. In particular, L2D2 attained 100 % detection rate and 11 % false positive rate on an extensive benchmark of hundreds of functions and millions of lines of code.