| 9.00 | Zahájení konference |
|---|---|
| 9.10 | Prezentace vybraných studentských prací I. |
| 10.40 | Přestávka s občerstvením |
| 11.00 | Prezentace vybraných studentských prací II. |
| 12.30 | Představení autorů odpolední přehlídky |
| 13.00 | Teplé občerstvení |
| 13.30 | Soutěžní přehlídka studentských prací formou plakátů a prototypů |
| 16.00 | Přestávka s občerstvením |
| 16.30 | Slavnostní vyhlášení výsledků a předání cen |
| 17.00 | Kulturní program - společenské setkávání, spolupráce, občerstvení, Rock na FIT |
| 22.00 | Předpokládaný konec akce |
V dopoledním bloku budou v hlavním sále konference autoři vybraných prací prezentovat své výsledky. Vybraní autoři v 15ti minutových prezentacích představí výsledky své tvůrčí činnosti.

![]()
![]()
![]()
Marek Žák
Hexapod, Legged chassis, Walking robot, Hexapod gaits
Robotika a umělá inteligence
This paper aims on design, construction and control of hexapod robot, which is six-leg walking robot. Basic characteristics of legged robots, a few existing robots and their pros and cons are described. Paper also describes basic gaits, which are used by legged robots for their locomotion. Result of this project is a legged robot, which can walk using tripod, wave and ripple gait and is equipped with sonars, force-sensitive resistors and encoders. Robot is controlled and monitored from user interface program. It can display data from sensors and positions of robot’s legs. The robot can be used to test and verify algorithms, gaits and features of walking robots.
![]()
![]()
Michal Wiglasz
Koevoluční algoritmus, Kartézské genetické programování, Genetický algoritmus, Plasticita fenotypu, Predikce fitness, Obrazový filtr
Nekonvenční výpočetní techniky
Kartézské genetické programování (CGP) se využívá zejména pro automatizovaný návrh číslicových obvodů, ale ukázalo se být úspěšnou metodou i pro řešení jiných inženýrských úloh. Časově nejnáročnější částí výpočtu je vyhodnocení kvality kandidátních řešení. Bylo ukázáno, že evoluci je možné urychlit pomocí koevoluce s prediktory fitness, které slouží k přibližnému určení kvality kandidátních řešení. Nevýhodou koevoluce je nutnost provést mnoho časově náročných experimentů pro určení nejvýhodnější velikosti prediktoru pro daný problém. V tomto článku je představena nová reprezentace prediktorů fitness s plastickým fenotypem, založená na principech souběžného učení v evolučních algoritmech. Plasticita fenotypu umožňuje odvodit různé fenotypy ze stejného genotypu. Díky tomu je možné adaptovat velikost prediktoru v průběhu evoluce na obtížnost řešeného problému. Z experimentů vyplývá, že lze dosáhnout srovnatelné kvality jako u standardního CGP při kratší době běhu programu a zároveň odpadá nutnost hledání nejvýhodnější velikosti prediktoru.

![]()
![]()
Tereza Černá
Detekce registračních značek vozidel, Klasifikace znaků, Kaskádový klasifikátor, MSER
Zpracování dat (obraz, zvuk, text apod.) Počítačová grafika
Cílem této práce je detekce registračních značek vozidel a rozpoznání jejich textu. Základním přístupem pro detekci je využití kaskádového klasifikátoru. Práce je rozdělena do tří hlavních kapitol -- získání datové sady, detekce značek a rozpoznání znaků. Datová sada byla pořízena na území města Brna přímo pro účely této práce a sloužila k trénování a vyhodnocení detektorů. Další dvě části pojednávají o přípravě pozitivních a negativních vzorků dat a jejich použití při trénování kaskádového klasifikátoru. Úspěšnost detekce registračních značek byla vyhodnocena na dvou datových sadách s výsledky 100 % a 98.47 %. Aktuálně se autorka zabývá rozpoznáním znaků a~sestavením registrační značky.

![]()
![]()
Jiří Hon
Příbuzné proteiny, Ověření funkce proteinu, Zachování aktivního místa
Bioinformatika
Hledání příbuzných enzymů v biologických databázích patří mezi obvyklé činnosti v oblasti proteinového inženýrství a pro tento účel existuje řada zavedených nástrojů. Chceme-li však stávajícími nástroji hledat příbuzné enzymy s modifikovanou funkcí - a zamýšlíme tím modifikaci pouze ve smyslu rychlosti reakce, stability enzymu apod., nikoliv přímo typu enzymatické funkce - pak spoléháme na slabou hypotézu, že sekvenčně podobné enzymy mají pravděpodobně stejný typ funkce. Důsledkem toho je buď příliš velké množství nežádoucích výsledků vyhledávání, nebo naopak jejich nedostatečná různorodost. Proto ve spolupráci s Loschmidtovými laboratořemi navrhuji rozšířit současné nástroje o nové filtrační kroky omezující výsledky pouze na relevantní enzymy, jejichž základem je zohlednění pozice a typu katalytických reziduí hledaného enzymu a doplnění anotací. Implementací a aplikací filtračních kroků se mi podařilo dosáhnout řádového snížení počtu výsledků při zachování jejich různorodosti a díky tomu jsem usnadnil a zlevnil výběr zajímavých sekvencí v množině nalezených putativních enzymů, které by mohly mít vhodné vlastnosti pro proteinové inženýrství a vyplatilo by se investovat do jejich experimentálního ověření v laboratoři.
![]()
![]()
Miloš Musil
Amino acid substitutions, Phylogenetic analysis, Mutations, Mutation effect prediction
Bioinformatika
Many genetic mutations are single nucleotide polymorphisms (SNPs). Significant number of genetic diseases is caused by non-synonymous SNPs manifested as single point mutations on the protein level. The ability to identify deleterious substitutions could be useful for protein engineering to test whether the proposed mutations do not damage protein function same as for targeting disease causing detrimental mutations. However the experimental validation is costly and the need of predictive computation methods has risen. Here we introduce a new in silico predictor based on the principles of phylogenetic analysis and dissimilarity between original and substituting amino acid physico-chemical properties. Developed algorithm was tested on four datasets with 78,650 mutations from 16,256 sequences in total. The predictor yields up to 72% normalized accuracy and in the comparison with the most existing tools, it is substantially less time consuming. In order to achieve the highest possible efficiency, the optimization process was focused on selection of the most suitable (a) overall decision threshold, (b) third-party software for calculation of a multiple sequence alignment and (c) a set of decision features / physico-chemical properties. To cope with the last mentioned problem, two feature selection methods were tested on the database of 544 possible properties.

![]()
![]()
![]()
David Kovařík
modeling, simulation, visualisation, data-flow graphs
Modelování a simulace Testování, analýza a verifikace
Data-flow graphs are, for their native support of high level of parallelism, often used by hardware designers. However, such graph representation is also very useful for performing deeper analysis of the design (including functional or formal verification). Simulator presented in this paper is a support tool for verification environment HADES. The goal of the simulator is to perform an efficient simulation of a verified model and to enhance user's knowledge about the model and its behavior. To perform a simulation efficiently, we introduce a specific simulation algorithm which saves computation time by eliminating redundant evaluations. The simulator is equiped with several output interfaces connected to a single simulation core. One output interface provides direct simulation output in text format. The second is also textual, but allows user to enter commands in order to control the simulation. Finally, the third forms a graphical interface in order to visualize results of simulation process. Thus, the simulator provides a scriptable command line interface to let users write automated tests as well as a powerful visualization tool for users to better understand behavior of the model.

![]()
![]()
Jakub Martiško
Grammar Systems, Parsing, Formal Languages
Překladače a gramatiky
Most commonly used parsers are based on the model of context free languages and grammars.This type of grammar is relatively simple to describe and design, however its descriptive poweris quite limited. One of the researched approaches, which deals with this problem are grammar systems. Using the combination of more simple grammars (usually context free), grammar systems are able to describe even some context sensitive languages while maintaining relative simplicity of context free grammars. This paper proposes modification of one of the variants of grammar systems. Parser, based on this modification, is also described in the paper. This proposed parser is able to parse same set of languages that are parseable by commonly used types of parsers and even some more complex languages.

![]()
![]()
Jan Vašíček
Odhad nadmořské výšky, Konvoluční sítě, EXIF data
Zpracování dat (obraz, zvuk, text apod.)
Tato práce se zabývá automatickým odhadem nadmořské výšky kamery z obrazu. Úlohu jsem řešil pomocí konvolučních neuronových sítí, u nichž využívám schopnost učit se nové příznaky na základě trénovacích dat. Trénovací sada obrazů (dataset), která by obsahovala údaje o nadmořské výšce kamery, nebyla k dispozici, a proto bylo nutné vytvořit dataset nový. Schopnosti člověka v dané úloze také nebyly dříve testovány, proto jsem provedl uživatelský experiment s cílem změřit průměrnou kvalitu lidského odhadu nadmořské výšky kamery. Experimentu se zúčastnilo 100 lidí a výsledky ukazují, že průměrná chyba odhadu člověka je 879m. Automatický systém založený na konvoluční neuronové síti dosahuje lepších výsledků než člověk, neboť průměrná chyba odhadu se pohybuje okolo hodnoty 751m. Navržený systém může kromě samotného odhadu nadmořské výšky z obrazových dat nalézt uplatnění také ve složitějších úlohách, jako je vizuální geo-lokalizace kamery.
![]()
![]()
![]()
Martin Šimon
object tracking, bidirectional tracking, partial occlusion, long-term tracking, full occlusion, rough camera movement
Zpracování dat (obraz, zvuk, text apod.) Počítačová grafika
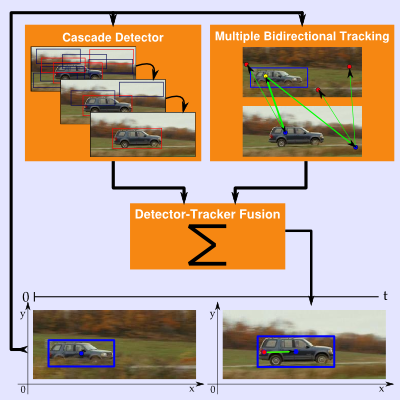
Visual object tracking with focus on occlusion, background clutter, image noise and unsteady camera movements, those all in a long-term domain, remain unsolved despite the popularity it experiences in recent days. This paper summarizes a related work which has been done in trackers field and proposes an object tracking system focused on solving mentioned problems, especially the occlusion, rough camera movements and the long-term task. To solve these problems we propose a system combined from three parts; the tracker, which is the core part, the detector, to re-initialize tracker after a failure or an occlusion, and a system of adaptive learning to handle long-term task. The tracker uses newly proposed approach of bidirectional tracking of points, which are generally weaker then commonly used keypoints. Outputs of both the tracker and the detector are fused together and the result is also used for the learning part. The proposed solution can handle mentioned problems well and in some areas is even better then the state-of-the-art solutions.
![]()
![]()
Petr Dvořáček
kartézské genetické programování, aproximační počítání, optimalizace
Počítačová architektura a vestavěné systémy Nekonvenční výpočetní techniky
V posledních letech klademe stále větší důraz na energetickou úspornost integrovaných obvodů. Můžeme vytvořit aproximační obvody, které nesplňují specifikovanou logickou funkci, a které jsou cíleně navrženy ke snížení plochy, zpoždění a příkonu. Tyto přibližně pracující obvody lze využít v mnoha aplikacích, kde lze tolerovat chyby, obzvláště ve zpracování obrazu. Tato práce popisuje evoluční návrh aproximačních obvodů pomocí kartézského genetického programování (CGP). Díky paralelnímu výpočtu fitness a různým akceleracím byla urychlena evaluace 8-bitové násobičky více než 170 krát oproti standardnímu přístupu. Pomocí inkrementální evoluce byly vytvořeny různé aproximační násobičky a použity v procesu potlačení nemaximálních hodnot v detekci hran.
![]()
![]()
Kateřina Žmolíková
speech recognition, deep neural networks, acoustic modelling
Zpracování dat (obraz, zvuk, text apod.)
This paper presents a modification of neural network structure in speech recognition system which leads to improving the accuracy of the system. Deep neural networks are widely used as a part of acoustic model which aims to predict the score of acoustic units given the speech signal. The input of deep neural network is a sequence of speech frames. Typically the network tries to classify the central one of these frames while using the context frames as an additional information. In the multiframe model the output of the network is extended to predict classes of multiple frames. This modification leads to obtaining multiple predictions for one frame. Combining these predictions results in better accuracy of the network. The approach was tested on Wall Street Journal dataset. Experimenting with different sizes of the context on the input and output of the network lead to 7% and 12% relative improvement on two testsets.

![]()
![]()
![]()
Jan Bednařík, David Herman
Human gesture recognition, Human tracking using depth sensor, Human tracking from top view, 3D human body pose, Human model fitting, Articulated human model, Depth sensor
Zpracování dat (obraz, zvuk, text apod.) Počítačová grafika
In this paper we present a system suitable for real-time human tracking and predefined human gestures detection using depth data acquired from Kinect sensor installed right above the detection region. The tracking part is based on fitting an articulated human body model to obtained data using particle filter framework and specifically defined constraints which originate in physiological properties of the human body. The gesture recognition part utilizes the timed automaton conforming to the human body poses and regarding tolerances of the joints positions and time constraints. The system was tested against the manually annotated 61-minutes-long recording of the depth data where ten different people were tracked. The 92.38\% sensitivity was reached as well as the real-time performance exceeding 30 FPS. No a priori knowledge about the tracked person is required which makes the system suitable for seamless human-computer interaction solutions, security applications or entertainment industry where the position of sensors must not interfere with the detection region.
Vybrané práce na soutěžní přehlídku budou prezentovány plakátem a často i demonstrátorem nebo prototypem řešení. Každý návštěvník tak bude mít možnost si autorská díla v klidu prohlédnout, osobně se s autorem práce setkat, zjistit si detaily řešení a prodiskutovat další možnosti a nápady.
V průběhu přehlídky bude probíhat hlasování o nejlepší práce v různých kategoriích. Každý návštěvník bude mít možnost vyjádřit svůj názor a volit v různých kategoriích.
| Jsem akademický nebo vědecký pracovník FIT. | Technologická úroveň Vědecký přínos Výborný nápad Společenský přínos |
| Jsem návštěvník ze sponzorské firmy. | Inovační potenciál Obchodní potenciál Výborný nápad Společenský přínos |
| Jsem běžný návštěvník. | Výborný nápad Společenský přínos |
Konkrétní způsob hlasování bude zveřejněn a představen až v den a místě konání soutěžní přehlídky.
V hlavním sále konference proběhne na závěr odpoledního bloku vyhlášení 5ti nejlepších prací v každé z 6ti kategorií a předání cen. Závěrečné pořadí prací určíte Vy, každý hlasující návštěvník konference Excel@FIT 2015, svýmy hlasy, které v průběhu přehlídky autorům udělíte.
Na závěr konference Excel@FIT proběhne na nádvoří FIT VUT doprovodný kulturní program.

![]()
![]()
Ondřej Soukup
simple matrix grammars, generative power, number of components
Překladače a gramatiky
The concept of simple matrix grammars was introduced and first studied in early seventies. All the achieved results were summarized in a few following studies and the simple matrix grammars start disappearing from the forefront. This work returns to them and aims to correct some generally accepted historical mistakes. In the following studies, the very first definition of simple matrix grammars has slightly evolved to the modern and currently generally accepted form, nevertheless, the validity of the former related results were not revised. However, these modifications have significant influence on the simple matrix grammars. Despite the existing beliefs that the simple matrix grammars define an infinite hierarchy of languages depending on the number of their components, we show that two components are exactly enough strong and the addition of another component do not increase the generative power. Moreover, we prove that simple matrix grammars with two components are precisely as strong as matrix grammars.
![]()
![]()
![]()
Marek Žák
Hexapod, Legged chassis, Walking robot, Hexapod gaits
Robotika a umělá inteligence
This paper aims on design, construction and control of hexapod robot, which is six-leg walking robot. Basic characteristics of legged robots, a few existing robots and their pros and cons are described. Paper also describes basic gaits, which are used by legged robots for their locomotion. Result of this project is a legged robot, which can walk using tripod, wave and ripple gait and is equipped with sonars, force-sensitive resistors and encoders. Robot is controlled and monitored from user interface program. It can display data from sensors and positions of robot’s legs. The robot can be used to test and verify algorithms, gaits and features of walking robots.
![]()
![]()
Vojtěch Havlena
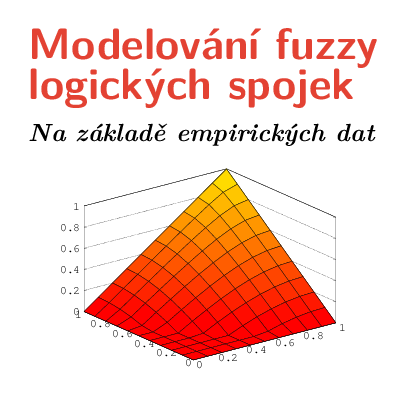
T-normy, Lawson-Hansonův algoritmus, Aproximace B-spliny
Modelování a simulace
Tento článek se věnuje způsobu modelování fuzzy logických spojek, speciálně fuzzy konjunkcí na základě empirických dat. Cílem je nalézt algoritmus pro aproximaci aditivních generátorů a pomocí něho experimentálně zjistit, jakým způsobem lidé chápou fuzzy konjunkci. Mimo určení, jaká fuzzy konjunkce nejvíce odpovídá konjunkci ve významu používaném lidmi, si experiment klade také za cíl zjistit, zda lidé chápou konjunkci jako komutativní operaci. V článku je představen a analyzován algoritmus, který na základě empirických dat hledá generátor, aproximovaný pomocí B-splinů, který těmto datům nejvíce odpovídá. Samotný experiment byl vyhodnocen na základě dat sesbíraných od respondentů.

![]()
![]()
Miroslav Slivka
SSL, TLS, šifrovaná komunikácia, Netfox
Počítačové sítě
Táto práca sa zaoberá sprístupnením šifrovanej komunikácie pre nástroj Netfox, ktorý vzniká na Fakulte informačních technologií, VUT v Brně pod záštitou bezpečnostného výskumu(VG20102015022) - SEC6NET. V práci je popísaná analýza SSL/TLS komunikácie a časť návrhu a implementácie samotného modulu. Implementácia zahrňuje niekoľko symetrických šifier a RSA, ktoré sa používa na výmenu kľúčov. Modul sprístupňuje šifrovanú komunikáciu pre ďalšie spracovanie a extrakciu dát v dešifrovanej podobe.

![]()
![]()
![]()
Juraj Kardoš
Aircraft ground dynamics, Ground motion model, AutoTaxi
Modelování a simulace
Recent studies focused on the global airline industry predict a continuous growth of passenger numbers, which will stimulate an increased demand for modern sophisticated aircraft capable of precise operations at reduced separation minima. Automation systems, such as AutoTaxi, will allow for decreased ground separation standards and a subsequent increase of throughput at airports in metropolitan areas. Such automation tools will also allow fuel savings by improving the way aircraft are operated on the ground. Except the direct operating cost, there are also associated effects, which need to be considered, namely, production of large volumes of CO2, noise pollution in the airport surroundings and an increased susceptibility to foreign object damage. This paper deals with an AutoTaxi control system for a single-aisle passenger aircraft, such as Boeing 737 series, under different operational conditions. The implemented model considers varying runway characteristics due to the atmospheric conditions and different aircraft configurations. The tire-ground interaction model has an essential impact on the ground motion model. Therefore we present detailed force and momentum equilibria analysis presented in form of equations of motion. The validation of the model was based on the turn radii comparison for multiple steering angles. Simulation results were subjected to a comparison with the analytical solution of the Ackerman drive for a tricycle vehicle and with Boeing turn radii as specified in Airplane Characteristics for Airport Planning. Obtained result suggest high-precision real-time simulation. The simulation model is assumed to be validated using actual real aircraft measured data from taxiing trials at designated international airport.
![]()
![]()
Michal Wiglasz
Koevoluční algoritmus, Kartézské genetické programování, Genetický algoritmus, Plasticita fenotypu, Predikce fitness, Obrazový filtr
Nekonvenční výpočetní techniky
Kartézské genetické programování (CGP) se využívá zejména pro automatizovaný návrh číslicových obvodů, ale ukázalo se být úspěšnou metodou i pro řešení jiných inženýrských úloh. Časově nejnáročnější částí výpočtu je vyhodnocení kvality kandidátních řešení. Bylo ukázáno, že evoluci je možné urychlit pomocí koevoluce s prediktory fitness, které slouží k přibližnému určení kvality kandidátních řešení. Nevýhodou koevoluce je nutnost provést mnoho časově náročných experimentů pro určení nejvýhodnější velikosti prediktoru pro daný problém. V tomto článku je představena nová reprezentace prediktorů fitness s plastickým fenotypem, založená na principech souběžného učení v evolučních algoritmech. Plasticita fenotypu umožňuje odvodit různé fenotypy ze stejného genotypu. Díky tomu je možné adaptovat velikost prediktoru v průběhu evoluce na obtížnost řešeného problému. Z experimentů vyplývá, že lze dosáhnout srovnatelné kvality jako u standardního CGP při kratší době běhu programu a zároveň odpadá nutnost hledání nejvýhodnější velikosti prediktoru.

![]()
![]()
Marek Milkovič
Unpacking, Decompilation, Retargetable Decompiler, Reverse Engineering, Executable Files, Packing, Malware, Compression
Překladače a gramatiky
Executable file packing is a process used for compression or protection of these files. The behavior and intent of such packed executable files is difficult or even impossible to analyze. If we want to analyze the original code, we need to detect the used packer and unpack the executable file with a tool called unpacker. This paper describes the methods used for packing and unpacking of the executable files as well as the implementation of an easily and quickly extensible unpacker, which is going to be used in a decompiler developed by AVG Technologies. This unpacker provides the interface for plugins, which extend the set of supported packers. Unpacking plugins aim at the methods for unpacking without actually running the packed program; thereby providing security measures and targeting the architecture and platform independent unpacking. A newly proposed generic unpacker achieves comparable results with unpackers used in practice and even outpace them in a few aspects. It shows that even static unpacking methods can produce accurate results.
![]()
![]()
Tereza Černá
Detekce registračních značek vozidel, Klasifikace znaků, Kaskádový klasifikátor, MSER
Zpracování dat (obraz, zvuk, text apod.) Počítačová grafika
Cílem této práce je detekce registračních značek vozidel a rozpoznání jejich textu. Základním přístupem pro detekci je využití kaskádového klasifikátoru. Práce je rozdělena do tří hlavních kapitol -- získání datové sady, detekce značek a rozpoznání znaků. Datová sada byla pořízena na území města Brna přímo pro účely této práce a sloužila k trénování a vyhodnocení detektorů. Další dvě části pojednávají o přípravě pozitivních a negativních vzorků dat a jejich použití při trénování kaskádového klasifikátoru. Úspěšnost detekce registračních značek byla vyhodnocena na dvou datových sadách s výsledky 100 % a 98.47 %. Aktuálně se autorka zabývá rozpoznáním znaků a~sestavením registrační značky.

![]()
![]()
Dominik Zapletal
Vehicle re-identification, Reacquisition, Multiple camera system, Vehicle signatures, Real time systems, Video surveillance, Computer vision, Feature extraction, Image matching, Road traffic
Zpracování dat (obraz, zvuk, text apod.) Počítačová grafika
In this paper an approach to the vehicle re-identification problem in a multiple camera system is presented. We focused on the re-identification itself assuming that the vehicle detection problem is already solved including extraction of a full-fledged 3D bounding box. The re-identification problem is solved by using color histograms, histograms of oriented gradients by a linear regressor. The features are used in separate models in order to get the best results in the shortest CPU computation time. The proposed method works with a high accuracy (60% true positives retrieved with 10% false positive rate on a challenging subset of the test data) in 85 milliseconds of the CPU (Core i7) computation time per one vehicle re-identification assuming the fullHD resolution video input. The applications of this work include finding important parameters like travel time, traffic flow, or traffic information in a distributed traffic surveillance and monitoring system.

![]()
![]()
Martin Hruška
Forest Automata, Formal Verification, Static Analysis, Complex Data Structures, Tree Automata, Backward Run, Predicate Abstraction
Testování, analýza a verifikace
Forest automata are one of the formalisms recently used for analysis and verification of programs manipulating dynamic data structures. In the area of shape analysis there exists a tool Forester employing forest automata. Forest automata are based on tree automata and Forester has its own implementation of tree automata. However, there is the VATA library which implements the efficient algorithms for the tree automata manipulation, especially the efficient algorithms for the checking inclusion of languages of tree automata what is an operation crucial also for the verification procedure based on forest automata. The first goal of this work is to implement a version of Forester tool that uses the VATA library for tree automata manipulation. The second goal of this work is to extend forest automata based verification with backward run that checks whether a found error is a spurious or a real one what could be used for refinement of predicate abstraction. The first goal has been already fulfilled and the variant of Forester using the VATA library successfully participated in the competition SV-COMP 2015. The part of the second goal is done only partially -- the backward run is already finished and predicate abstraction implementation is in progress.
![]()
![]()
Jiří Hon
Příbuzné proteiny, Ověření funkce proteinu, Zachování aktivního místa
Bioinformatika
Hledání příbuzných enzymů v biologických databázích patří mezi obvyklé činnosti v oblasti proteinového inženýrství a pro tento účel existuje řada zavedených nástrojů. Chceme-li však stávajícími nástroji hledat příbuzné enzymy s modifikovanou funkcí - a zamýšlíme tím modifikaci pouze ve smyslu rychlosti reakce, stability enzymu apod., nikoliv přímo typu enzymatické funkce - pak spoléháme na slabou hypotézu, že sekvenčně podobné enzymy mají pravděpodobně stejný typ funkce. Důsledkem toho je buď příliš velké množství nežádoucích výsledků vyhledávání, nebo naopak jejich nedostatečná různorodost. Proto ve spolupráci s Loschmidtovými laboratořemi navrhuji rozšířit současné nástroje o nové filtrační kroky omezující výsledky pouze na relevantní enzymy, jejichž základem je zohlednění pozice a typu katalytických reziduí hledaného enzymu a doplnění anotací. Implementací a aplikací filtračních kroků se mi podařilo dosáhnout řádového snížení počtu výsledků při zachování jejich různorodosti a díky tomu jsem usnadnil a zlevnil výběr zajímavých sekvencí v množině nalezených putativních enzymů, které by mohly mít vhodné vlastnosti pro proteinové inženýrství a vyplatilo by se investovat do jejich experimentálního ověření v laboratoři.
![]()
![]()
Miloš Musil
Amino acid substitutions, Phylogenetic analysis, Mutations, Mutation effect prediction
Bioinformatika
Many genetic mutations are single nucleotide polymorphisms (SNPs). Significant number of genetic diseases is caused by non-synonymous SNPs manifested as single point mutations on the protein level. The ability to identify deleterious substitutions could be useful for protein engineering to test whether the proposed mutations do not damage protein function same as for targeting disease causing detrimental mutations. However the experimental validation is costly and the need of predictive computation methods has risen. Here we introduce a new in silico predictor based on the principles of phylogenetic analysis and dissimilarity between original and substituting amino acid physico-chemical properties. Developed algorithm was tested on four datasets with 78,650 mutations from 16,256 sequences in total. The predictor yields up to 72% normalized accuracy and in the comparison with the most existing tools, it is substantially less time consuming. In order to achieve the highest possible efficiency, the optimization process was focused on selection of the most suitable (a) overall decision threshold, (b) third-party software for calculation of a multiple sequence alignment and (c) a set of decision features / physico-chemical properties. To cope with the last mentioned problem, two feature selection methods were tested on the database of 544 possible properties.

![]()
![]()
![]()
Ladislav Mošner
3D printing, delta printer, Fused Deposition Modeling, Fused Filament Fabrication, RepRap
Počítačová architektura a vestavěné systémy
This paper deals with the topic of 3D printing. The primary aim was to build a real printer with a stiff construction minimizing clearance. The design of the 3D printer and its parts was highly influenced by the RepRap project, especially by the Rostock printer based on the delta kinematics, and Fused Deposition Modeling. The solution is formed using the Arduino Mega 2560 platform running Marlin firmware. Our printer uses a newly designed extruder that should prevent a filament from melting in a guide tubule due to a large heatsink. In order to evaluate the accuracy of the 3D printer, multiple tests were performed. The advantages and weaknesses of the modified design presented here can be very helpful for other people who may decide to build their own 3D printer.

![]()
![]()
![]()
Jan Krušina
Braille Font Detection, Braille Reader, Mobile Device
Zpracování dat (obraz, zvuk, text apod.)
The aim of this project is to create a portable Braille reader. The main objective is to recognize Braille characters from images taken by camera on a mobile phone, convert them into Latin alphabet, and eventually display the output to the user. Solution of this task is based on a visual detection of Braille characters. Input frames from camera are processed one by one using a special algorithm which separates dots in characters from the rest of the image. Afterwards, dots are grouped into particular characters. Finally, every single character is translated and rendered on screen. This application is capable of detecting dots from books at a very high success rate. Reading from other surfaces, e.g., metal, has a good success rate as well. Thus, the application is able to detect dots on informational signs and other captions, which are commonly used. This reader gives people the ability to read text written in Braille used by blind and visually impaired people all over the world.

![]()
![]()
Zdeněk Hladík
finite automata, twodimensional languages, car nationality, licence plates
Zpracování dat (obraz, zvuk, text apod.) Překladače a gramatiky
Cílem této práce je aplikace umožňující zjistit státní příslušnost automobilu na základě tvaru jeho SPZ. Aplikace využívá dvoudimensionálních konečných automatů a současně vytvořenou obsáhlou databázi povolených tvarů SPZ evropských států. V současné době aplikace podporuje 27 států a cca 9000 příslušných pravidel. Využití této aplikace je např. pro mýtné brány, bezpečnostní záznamy nebo statistiky provozu. Jedná se o demostrační příklad využití dvoudimensionálních automatů a operací s 2-D řetězci v praxi pro komerční využití.

![]()
![]()
![]()
Lenka Jalůvková
Spojování snímků, SIFT, SURF, RANSAC, Planární projekce, Cylindrická projekce
Zpracování dat (obraz, zvuk, text apod.)
Tento článek je zaměřen na tvorbu živých panoramat. Vstupem je video ze streamujících kamer, výstupem je taktéž stream - panorama neustále se překreslující podle aktuální polohy kamery. Výsledné řešení je založeno na algoritmech SIFT a SURF pro hledání klíčových bodů a deskriptorů ve snímcích, dále na algoritmu RANSAC pro výpočet homografie sloužící k následnému plynulému spojování snímků a splynutí přechodů. Překreslování snímků zleva doprava i zprava doleva vyžadovalo váhování přechodů z obou stran vkládaného snímku. Tvorba panoramat je závislá na zvolené obrazové projekci, v našem případě byla použita planární a cylindrická projekce. Funkčnost navrhnutého řešení byla otestována na řadě testovacích nahrávek.
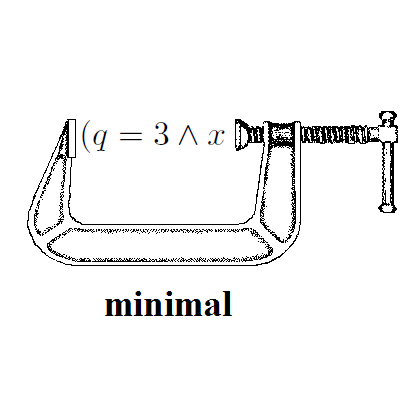
![]()
![]()
Lenka Turoňová
Parallel systems, Formal verification, Petri nets, Coverability, Abstraction, Well-quasi-ordered transition systems
Testování, analýza a verifikace
We improve existing method for the automatic verification of systems with parallel running processes. The technique is based on an effort to find an inductive invariant using a variant of counterexamplequided refinement (CEGAR). The effectiveness of the method depends on the size of the invariant. In this paper, we explore the possiblity of improving the method by focusing on finding the smallest invariant.

![]()
![]()
Karel Beneš
Grammar-based language model, Push-to-talk button, Automatic Speech Recognition
Zpracování dat (obraz, zvuk, text apod.)
This paper describes the construction of a speech recognition system for usage in the aeronautics cockpit. The primary goal of the recognizer is to allow pilots to control parts of the cockpit by voice. Speech recognition in the cockpit is challenging, because of changing context, variable noise and the possibility of off-talk. The recognizer is based on the Kaldi speech recognition toolkit and several project-specific components are implemented in C++. Additionally, a specific way of creating language model for coping with noises is presented. In general, we describe how to use a research-oriented speech recognition toolkit in a real-world application.

![]()
![]()
![]()
Jakub Adámek
Počítání kolonií, Analýza Petriho misek, Zpracování obrazu
Zpracování dat (obraz, zvuk, text apod.)
Analýza Petriho misek je jednou ze základních úloh v mikrobiologických laboratořích, avšak nikoli nejjednodušší. Správná analýza a vyhodnocení Petriho misek může přispět k záchraně lidského života. Práce se zabývá automatickou analýzou obrazu Petriho misek a počítáním bakteriálních kolonií. Cílem práce je vytvořit mobilní aplikaci a případná příslušenství, která by byla schopná konkurovat komerčním řešením. ColonyCatcher je aplikace určená pro mobilní zařízení se systémem Android, která je schopná pomocí spodní osvětlovací jednotky pořídit snímek Petriho misky a nadále jej analyzovat a určit počet bakteriálních kolonií. Součástí práce je popis osvětlovací jednotky a také algoritmů, které jsou použity pro počítání bakteriálních kolonií. Následuje popis použití aplikace ColonyCatcher, která provede laboranta analýzou Petriho misky v pěti snadných krocích. Přínosem práce je dostupnější aplikace a její příslušenství pro všechny mirkobiologické laboratoře.

![]()
![]()
Radim Kocman
jumping finite automata, n-parallel languages, discontinuous tape reading
Překladače a gramatiky
The present paper proposes an idea for a new investigation area in automata theory — n-parallel jumping finite automata. These automata are a combination of recently presented jumping finite automata and more settled n-parallel grammars. They read input words discontinuously as general jumping finite automata; however, they use multiple heads to do so, which is quite similar to the principle of the multiple nonterminals in n-parallel right linear grammars. This paper establishes definitions for such automata, outlines expected results, and suggests future investigation areas.
![]()
![]()
![]()
David Kovařík
modeling, simulation, visualisation, data-flow graphs
Modelování a simulace Testování, analýza a verifikace
Data-flow graphs are, for their native support of high level of parallelism, often used by hardware designers. However, such graph representation is also very useful for performing deeper analysis of the design (including functional or formal verification). Simulator presented in this paper is a support tool for verification environment HADES. The goal of the simulator is to perform an efficient simulation of a verified model and to enhance user's knowledge about the model and its behavior. To perform a simulation efficiently, we introduce a specific simulation algorithm which saves computation time by eliminating redundant evaluations. The simulator is equiped with several output interfaces connected to a single simulation core. One output interface provides direct simulation output in text format. The second is also textual, but allows user to enter commands in order to control the simulation. Finally, the third forms a graphical interface in order to visualize results of simulation process. Thus, the simulator provides a scriptable command line interface to let users write automated tests as well as a powerful visualization tool for users to better understand behavior of the model.

![]()
![]()
Martin Sladeček
Správa času, First Things First, Android Wear, Android kalendář, Android todo list, Google Calendar API
Uživatelská rozhraní
Práce popisuje návrh a implementaci mobilní aplikace na správu času. Koncept správy času vychází z filosofie First-Things-First, která má za cíl nejen pomoci s plánováním času, ale vést uživatele k sebezdokonalování. Na rozdíl od většiny dostupných kalendářů a todo listů je v této aplikaci každý úkol či událost podřízena krátkodobým či dlouhodobým cílům. Aplikace je dostupná pro mobilní telefony a tablety se systémem Android a podporuje i chytré hodinky s Android Wear. Práce má za úkol seznámit čtenáře s filosofií First-Things-First a nastínit problematiku spojenou s návrhem a implementací mobilní aplikace.

![]()
![]()
Dominik Šimek
Intel Xeon Phi, HPC, N-Body, k-Wave
Počítačová architektura a vestavěné systémy
Motiváciou pre vznik tejto práce bolo nasadenie a optimalizácia výpočtovo náročných algoritmov na koprocesor Intel Xeon Phi. Tabuľkovo koprocesor Intel Xeon Phi disponuje podstatne väčším výkonom ako klasický procesor, preto sa javí ako veľmi zaujímavá architektúra. Celkovo je táto technológia veľmi mladá a ešte neprebádaná, preto stojí za úsilie priniesť pohľad, ktorý by zjednodušil prácu s koprocesorom a umožnil jeho efektívne využívanie. Cieľom tohto dokumentu je stručne oboznámiť čitateľa s našou prácou, ktorá by mohla byť v blýzkej budúcnosti veľmi zaujímavá a využiteľná. Na koľko je Intel Xeon Phi mladou technológiou, jeho efektívne využívanie je pomerne náročné. Práca sa teda javí ako veľká výzva, ktorú by bola škoda nevyužiť. Práca s koprocesorom Intel Xeon Phi má budúcnosť v obore High Performance Computing, kde by ho bolo možné používať napríklad na miesto akcelerátorov GPGPU. Vysoko optimalizované výpočtovo náročné algoritmy by teda mali bežať na tomto koprocesore veľmi rýchlo. Aká je ale pravda? Je vysoký výkon koprocesoru naozaj využiteľný? V bakalárskej práci sme postupovali od jednoduchších benchmarkov k zložitejším problémom, ktoré sme sa snažili dôkladne vyhodnotiť. K zaujímavejším problémom riešených v tejto práci patrí napríklad simulácia pohybu častíc v priestore (N-Body), simulácia šírenia akustických vĺn v 1D, 2D a 3D, optimalizácia extrakcie ivectoru, ktorá sa využíva pri spracovaní reči.
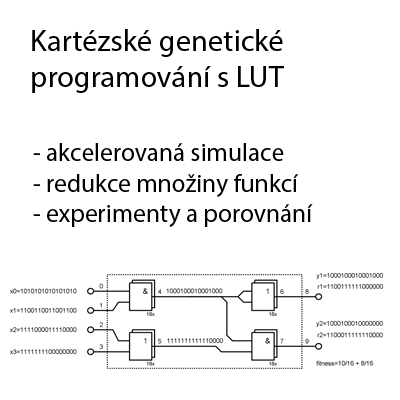
![]()
![]()
Karolína Hajná
kartézské genetické programování, třívstupové LUT, návrh obvodů
Robotika a umělá inteligence
Tato práce se zabývá problematikou návrhu obvodů pomocí kartézského genetického programování na úrovní třívstupových logických členů. Je představena metoda bitově paralelní akcelerace výpočtu fitness pro obvody s třívstupovými hradly. Porovnáním její vlastnosti s nejpoužívanější variantou kartézského genetického programování, které používá dvouvstupová hradla, jsou ukázány výhody a nevýhody této metody. Výsledky by mohly přinést nové možnosti při návrhu obvodů.
![]()
![]()
Jakub Martiško
Grammar Systems, Parsing, Formal Languages
Překladače a gramatiky
Most commonly used parsers are based on the model of context free languages and grammars.This type of grammar is relatively simple to describe and design, however its descriptive poweris quite limited. One of the researched approaches, which deals with this problem are grammar systems. Using the combination of more simple grammars (usually context free), grammar systems are able to describe even some context sensitive languages while maintaining relative simplicity of context free grammars. This paper proposes modification of one of the variants of grammar systems. Parser, based on this modification, is also described in the paper. This proposed parser is able to parse same set of languages that are parseable by commonly used types of parsers and even some more complex languages.

![]()
![]()
Dominik Breitenbacher
Faktorizace, SIQS, OpenMP, MPIR, Profilace
Bezpečnost
Práce se zabývá faktorizací celých čísel, tedy rozkladem složeného čísla na jeho faktory. Faktorizace je nejznámější a nejpoužívanější metodou k lámání RSA. V rámci této práce byla vybrána faktorizační metoda zvaná SIQS. SIQS je považována za nejrychlejší metodu k faktorizaci čísel, které mají do 100 dekadických číslic, a tato metoda byla v rámci práce i naimplementována. Implementace byla řádně zdokumentována, čímž se práce snaží vyplnit mezeru mezi teoretickým popisem SIQS a existujícími implementacemi. I když se jedná o nejrychlejší metodu (do 100 číslic), není možné ji efektivně počítat v polynomiálním čase, a tak se hledají různé možnosti, jak tuto metodu co nejvíce urychlit. Jako první se nabízí paralelizace. K tomuto účelu bylo využito OpenMP jakožto výkonného nástroje pro práci s vlákny, jeho použití je přitom velice jednoduché. Další možností je pak optimalizace kódu. Cílem této práce je ukázat, jak jednoduše lze v mnoha případech využít paralelizace kódu a dále také, jak díky podrobné analýze kódu lze dosáhnout poměrně velkého urychlení. Metodika iteračního provádění optimalizací se ukázala jako velmi účinná a je možné ji použít obecně, nejenom v této úloze. Touto metodikou byla implementace SIQS vylepšena tak, že faktorizace byla urychlena až 99-krát, v některých částech kódu dokonce ještě více.

![]()
![]()
![]()
Adam Babinec
Vehicle Detection, Vehicle Tracking, UAV, Aerial Imagery, Particle Filter
Zpracování dat (obraz, zvuk, text apod.) Robotika a umělá inteligence
In this paper we present a complex solution to automatic vehicle trajectory extraction from aerial video data, providing a basis for a cost-effective and flexible way to gather detailed vehicle trajectory data in traffic scenes. The video sequences are captured using an action camera mounted on a UAV flying above the traffic scene and processed off-line. The system utilizes video stabilisation algorithm and geo-registration based on RANSAC guided transformation estimation of ORB image feature sets. Vehicles are detected in scene using AdaBoost classifier constructed of Multi-Scale Block Local Binary Patterns features. The vehicle tracking is carried out by multi-target tracker based upon set of intra-independent Bayesian bootstrap particle filters specialized to deal with environmental occlusion, multi-target overlap, low resolution and feature salinity of targets and their appearance changes. The performance of the presented system was evaluated against hand-annotated video sequences captured in distinct traffic scenes. The analysis show promising results with average target miss ratio of 22.5 % while keeping incorrect tracking ratio down to 20.4 %.
![]()
![]()
Jan Vašíček
Odhad nadmořské výšky, Konvoluční sítě, EXIF data
Zpracování dat (obraz, zvuk, text apod.)
Tato práce se zabývá automatickým odhadem nadmořské výšky kamery z obrazu. Úlohu jsem řešil pomocí konvolučních neuronových sítí, u nichž využívám schopnost učit se nové příznaky na základě trénovacích dat. Trénovací sada obrazů (dataset), která by obsahovala údaje o nadmořské výšce kamery, nebyla k dispozici, a proto bylo nutné vytvořit dataset nový. Schopnosti člověka v dané úloze také nebyly dříve testovány, proto jsem provedl uživatelský experiment s cílem změřit průměrnou kvalitu lidského odhadu nadmořské výšky kamery. Experimentu se zúčastnilo 100 lidí a výsledky ukazují, že průměrná chyba odhadu člověka je 879m. Automatický systém založený na konvoluční neuronové síti dosahuje lepších výsledků než člověk, neboť průměrná chyba odhadu se pohybuje okolo hodnoty 751m. Navržený systém může kromě samotného odhadu nadmořské výšky z obrazových dat nalézt uplatnění také ve složitějších úlohách, jako je vizuální geo-lokalizace kamery.

![]()
![]()
Peter Matula
reverse engineering, decompilation, data type recovery, cryptographic constants
Bezpečnost
Retargetable machine-code decompilation transforms a platform-independent executables into a high level language (HLL). Decompilers may be used by reverse engineers to manually inspect suspicious binaries (e.g. malicious software). However, modern malware is often very complex and its decompilation produces huge and enigmatic outputs. Therefore, reverse engineers are trying to use every bit of available information to aid their analysis. This paper presents a fast cryptographic constants searching algorithm. Based on the signature database, it recognises usage of constants typical for many well-known (cryptographic, compression, etc.) algorithms. Moreover, the results are used by AVG Retargetable Decompiler to make its output more readable. The presented algorithm is faster than any state-of-the-art solution and it is fully exploited in the decompilation process.
![]()
![]()
![]()
Martin Šimon
object tracking, bidirectional tracking, partial occlusion, long-term tracking, full occlusion, rough camera movement
Zpracování dat (obraz, zvuk, text apod.) Počítačová grafika
Visual object tracking with focus on occlusion, background clutter, image noise and unsteady camera movements, those all in a long-term domain, remain unsolved despite the popularity it experiences in recent days. This paper summarizes a related work which has been done in trackers field and proposes an object tracking system focused on solving mentioned problems, especially the occlusion, rough camera movements and the long-term task. To solve these problems we propose a system combined from three parts; the tracker, which is the core part, the detector, to re-initialize tracker after a failure or an occlusion, and a system of adaptive learning to handle long-term task. The tracker uses newly proposed approach of bidirectional tracking of points, which are generally weaker then commonly used keypoints. Outputs of both the tracker and the detector are fused together and the result is also used for the learning part. The proposed solution can handle mentioned problems well and in some areas is even better then the state-of-the-art solutions.

![]()
![]()
Ondřej Krpec
Plagiarism, PHP, Plagiarism detection in PHP code, Code obfuscation, Haelstead metrics, Levenshtein algorithm, Document fingerpring, Winnowing algorithm, Tokenization, Abstract syntax tree
Zpracování dat (obraz, zvuk, text apod.) Překladače a gramatiky
This project develops a system for detecting plagiarism in sets of student assignments written in PHP language. Plagiarism is viewed as a form of code obfuscation where students deliberately perform semantics preserving transformations of an original working version to pass it off as their own. In order to detect such obfuscations we develop a tool in which we attempt to find transformations that have been applied, using several techniques and algorithms. The main goal is to provide fast and quality tool for plagiarism recognition that can be used at academic enviroment.
![]()
![]()
Martin Holkovič
SDN, dynamická identita, Pyretic, OpenFlow
Počítačové sítě
Jedným z posledných trendov firemných počítačových sietí je možnosť zapojiť si vlastné zariadenie do siete. Tento trend otvára nové výzvy pre sieťových administrátorov. Jedným z prístupov ako sa k~problému so správou veľmi dynamických sietí vysporiadať je správa pomocou identít používateľov. Namiesto vytvárania konfigurácie sieťových prvkov na základe pripojených koncových staníc (MAC adresa, IP adresa) sa konfigurácia vytvára podľa identity užívateľov, využívajúcich koncové stanice (meno užívateľa, pracovná skupina). Výsledkom práce je rožšírenie riadenia SDN sietí o znalosť identít používateľov pomocou systému pre detekciu a správu identít. Takto rozšírené riadenie umožňuje administrátorovi konfigurovať a spravovať sieť prostredníctvom identity používateľov. Súčasťou práce je taktiež vytvorenie prípadu použitia znázorňujúceho výhody tohto prístupu.

![]()
![]()
Věra Müllerová
HDR, high dynamic range imaging, de-ghosting, FPGA, real-time, video
Zpracování dat (obraz, zvuk, text apod.)
High dynamic range (HDR) imaging technology is becoming increasingly popular in recent years. A~standard and most common approach to obtain an HDR image is the multiple exposures fusion method that consists of combining multiple images of the same scene captured with different exposure times. This technique works perfectly only on static scenes. However, if there is a motion in the scene during the sequence acquisition, the resultant HDR image contains ghosting artefacts due to moving objects in the captured scene. In this paper, de-ghosting methods are reviewed and two of them - a bitmap movement detection based on a median threshold and a histogram based ghost detection - are proposed as the suitable techniques for a real-time video capturing and implementation on an FPGA (Field-Programmable Gate Array) architecture.
![]()
![]()
Petr Šebek, Martin Hrubý
Genetic Algorithm, Resource-Constrained Project Scheduling Problem, GARTH
Modelování a simulace
In this paper, I study the resource-constrained project scheduling problem and describe the novel genetic algorithm GARTH created by Martin Hrubý. GARTH is designed to find and eliminate unfavorable characteristics from an individual. This approach is opposing the standard way of thinking about genetic algorithms - to synthesize desirable characteristic in new individuals. To be able to recognize unfavorable characteristics, the algorithm creates a hypothesis about mutual time properties of particular jobs from the given problem instance. This hypothesis is called Run Time Hypothesis because it is created as the algorithm get to know specific problem instance. The topic of my paper is to develop this algorithm and to discover new techniques that could be used in computation of RCPSP.
![]()
![]()
Petr Dvořáček
kartézské genetické programování, aproximační počítání, optimalizace
Počítačová architektura a vestavěné systémy Nekonvenční výpočetní techniky
V posledních letech klademe stále větší důraz na energetickou úspornost integrovaných obvodů. Můžeme vytvořit aproximační obvody, které nesplňují specifikovanou logickou funkci, a které jsou cíleně navrženy ke snížení plochy, zpoždění a příkonu. Tyto přibližně pracující obvody lze využít v mnoha aplikacích, kde lze tolerovat chyby, obzvláště ve zpracování obrazu. Tato práce popisuje evoluční návrh aproximačních obvodů pomocí kartézského genetického programování (CGP). Díky paralelnímu výpočtu fitness a různým akceleracím byla urychlena evaluace 8-bitové násobičky více než 170 krát oproti standardnímu přístupu. Pomocí inkrementální evoluce byly vytvořeny různé aproximační násobičky a použity v procesu potlačení nemaximálních hodnot v detekci hran.

![]()
![]()
Petr Heřman
Levný robot, Firmware řídící a senzorové jednotky, PIC mikrokontrolér, ROS
Robotika a umělá inteligence
Tato práce popisuje návrh robota z cenově dostupného materiálu. Implementaci firmware vlastní jednotky nižšího řízení založené na mikrokontroléru PIC, která má na starost řízení motorů, získávání dat ze senzorů a komunikaci s jednotkou vyššího řízení. Dále se věnuje realizaci napojení na robotický operační systém ROS a jeho standardní struktury umožňující využití existujících balíčku pro ovládání robota a zobrazování dat z jeho senzorů. Vyrobený robot je modelem automatické sekačky trávníku, ale celé řešení je univerzální. Řídící a senzorovou jednotku, jež je spojovací komponentou mezi podvozkem a počítačem s ROS, lze bez větších obtíží využít i u jiných robotů.

![]()
![]()
Barbora Franková
Softwarově definované sítě, OpenFlow, OpenDaylight, Zákonné odposlechy, Sec6Net
Počítačové sítě
Tato práce se zabývá využitím softwarově definovaných sítí v oblasti zákonných odposlechů. Staví na implementaci systému pro zákonné odposlechy vyvinuté v rámci projektu Sec6Net. Přínosem práce je rozšíření tohoto systému v několika oblastech, ve kterých SDN nabízí potenciál ke spolehlivější identifikaci odposlouchávaných uživatelů a efektivnějšímu využití sítě. První zmíněný cíl je realizován prostřednictvím modulu funkce dynamické identity, druhý pak pomocí modulu pro dynamickou konfiguraci síťových sond.
![]()
![]()
Miroslav Skácel
Query-by-Example, Spoken Term Detection, Dynamic Time Warping, acoustic pattern search, unsupervised detection in speech
Zpracování dat (obraz, zvuk, text apod.)
This paper aims at a search in a large speech database with zero or low-resource languages by spoken term example in a spoken utterance. The data can not be recognized by Automatic Speech Recognition system due to a lack of resources. A modern method for searching patterns in speech called Query-by-Example is investigated. This technique exploits a well-known dynamic programming approach named Dynamic Time Warping. An analysis of different distance metrics used during the search is provided. A scoring metric based on normalized cross entropy is described to evaluate the system accuracy.

![]()
![]()
![]()
Václav Pfudl
real-time rendering, normal-mapping, shadow-mapping, lens-flare, screen space ambient occlusion, skydome, skeletal animation, movement artificial intelligence, group behaviors
Počítačová grafika
The aim of this text was to describe implementation of software that would be able to simulate a scene with walking characters in real-time with emphasis on rendering level of realism. The application should be then able to record video sequences of such simulated scenes. Such video sequences could be used as an input (test data) for people counting systems. The problem was divided into three major subproblems: character animation, artificial intelligence for character movement and advanced rendering techniques. The character animation problem is solved by creating a model of the character and using skeletal animation. To achieve characters moving in a scene autonomously path finding (A* algorithm) and group behaviors (steering behaviors) were implemented. Realism in a scene is added by implemented rendering methods such as normal-mapping, shadow-mapping, deffered rendering, skydome, lens flare effect and screen space ambient occlusion. Rendering stage of a scene can be easily parametrized through implemented GUI. Implemented application provides user with easy way of setting a scene with walking pedestrians, setting its visualization and to record the result.
![]()
![]()
Kateřina Žmolíková
speech recognition, deep neural networks, acoustic modelling
Zpracování dat (obraz, zvuk, text apod.)
This paper presents a modification of neural network structure in speech recognition system which leads to improving the accuracy of the system. Deep neural networks are widely used as a part of acoustic model which aims to predict the score of acoustic units given the speech signal. The input of deep neural network is a sequence of speech frames. Typically the network tries to classify the central one of these frames while using the context frames as an additional information. In the multiframe model the output of the network is extended to predict classes of multiple frames. This modification leads to obtaining multiple predictions for one frame. Combining these predictions results in better accuracy of the network. The approach was tested on Wall Street Journal dataset. Experimenting with different sizes of the context on the input and output of the network lead to 7% and 12% relative improvement on two testsets.
![]()
![]()
![]()
Jan Bednařík, David Herman
Human gesture recognition, Human tracking using depth sensor, Human tracking from top view, 3D human body pose, Human model fitting, Articulated human model, Depth sensor
Zpracování dat (obraz, zvuk, text apod.) Počítačová grafika
In this paper we present a system suitable for real-time human tracking and predefined human gestures detection using depth data acquired from Kinect sensor installed right above the detection region. The tracking part is based on fitting an articulated human body model to obtained data using particle filter framework and specifically defined constraints which originate in physiological properties of the human body. The gesture recognition part utilizes the timed automaton conforming to the human body poses and regarding tolerances of the joints positions and time constraints. The system was tested against the manually annotated 61-minutes-long recording of the depth data where ten different people were tracked. The 92.38\% sensitivity was reached as well as the real-time performance exceeding 30 FPS. No a priori knowledge about the tracked person is required which makes the system suitable for seamless human-computer interaction solutions, security applications or entertainment industry where the position of sensors must not interfere with the detection region.

![]()
![]()
Jakub Špaňhel
License plate detection, License plate recognition, Character segmentation, Character recognition, Intesity profiles, Neural network recognition, Cascade classifiers
Zpracování dat (obraz, zvuk, text apod.)
This paper aims at proposing an Automatic License Plate Recognition system (ALPR) from still images. This ALPR system is based on license plate detection by a cascade classifier and neural network (NN) license plate recognition. The system was developed in multiple iterations and different methods of license plate detection and character recognition were used for each of them. Comparison of the methods used is also presented. First of all, license plate location is estimated using cascade classifier. Secondly, individual characters are separated from the detected license plate. Finally, each of the separated characters is recognized using neural network. The system achieves an average precision rate of 88.94% for license plate detection, 83.81% for license plate recognition and has the an average success rate of 74.55% in total. This paper describes different solutions to license plate detection and recognition issues and compares some of the commonly used methods in this field.

![]()
![]()
![]()
Tomáš Poledník
Fire detection, Image processing, Video sequence, Machine Learning by deep convolutional neural networks, Computer vision, Caffe, Fire modelling, Fire scene compositing
Počítačová grafika
This paper deals with fire detection in image and video by machine learning, specifically deep convolutional neural networks, using Caffe framework. The aim is to create a vast set of testing data that could be used as the base element of machine learning detection and create a detector usable in real-time application. For the purposes of the project a set of tools for fire sequences creation, their segmentation and automatic labeling is proposed and created together with a large test set of short sequences with artificial modelled fire.
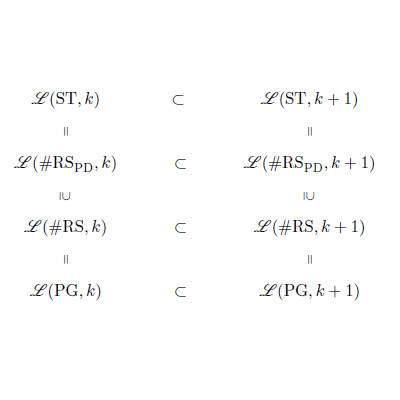
![]()
![]()
Jiří Kučera
rewriting systems, state grammars, pure pushdowns, infinite hierarchy
Informační systémy
The aim of this paper is to present a~modification of #-rewriting systems, called #-rewriting systems with pure pushdowns, and their relation to state grammars. Briefly, the #-rewriting systems with pure pushdowns are #-rewriting systems equiped with pushdowns containing only terminal symbols (herefrom comes their denomination as 'pure'), and a pushdown containing terminal and nonterminal symbols, which is used as an auxiliary workspace. It will be shown that this extension leads to relation between programmed grammars and state grammars.